Hello,
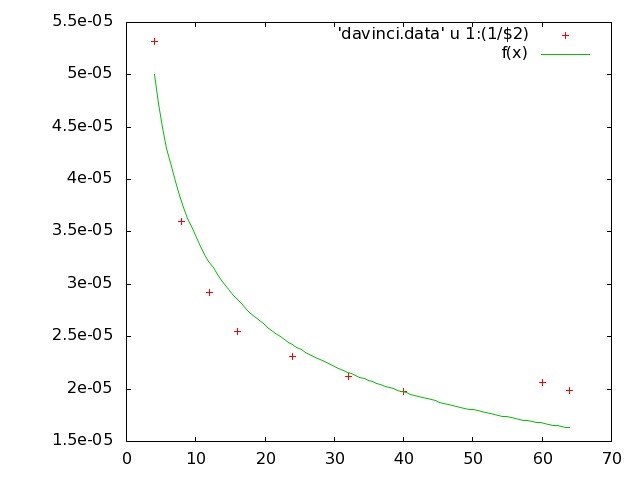
I performed some test run to see how many processor should I use for my problem. Following is what I observed:
number number processor
of of grid
processors dynamic
steps in
an hour
4 18800 1x2x2
8 27750 2x2x2
12 34250 2x2x3
16 39200 2x2x4
#20 30500 2x2x5
24 43350 2x3x4
#28 42050 2x2x7
32 47200 2x4x4
#36 43450 2x3x4
40 50600 2x4x5
#44 45950 2x2x11
#48
#52 39350 2x2x13
#56 40700 2x4x7
60 48500 3x4x5
64 50450 4x4x4
a simple fit reveals: time/step ~ 1/(sqrt(# of processors))
However, not all choices of number of processors is a good choice, e.g. using 20 processors takes longer than 16 processors.
Wondering if there is way I can choose processor grid and if this is related to time/step ? Is there also some relationship between total
number of atoms and max number of processor that could be used ? The above calculations were performed on 464 atoms.
I have also attached time/step (in hours) vs number of processors plot with this email.
Please let me know.
Thank you,
Vivek