I am writing to seek for suggestions about plugins for run_style.
I am interested in implementing a run_style similar to verlet/split, but making the partition for kspace use more processors than that for pair. It is useful for cases with slow pair style, for example, machine learning potentials. But I find that there is no straightforward way to implement a new run_style in plugin mode. We are currently add a new command add_run_style and introduce the new run_style in an indirect way. I am wondering whether you would like to have this feature (i.e., user-defined run_style) somehow, or prefer to leave it as a custom feature.
I can’t say much about the plugin architecture in general, but it’s hard for me to foresee how your suggestion would improve performance for your use case.
ML potentials typically have much shorter cutoffs than analytical potentials. So there should be less penalty for splitting an ML potential calculation over more processors (since each processor doesn’t need to replicate as much “skin” from other processors’ blocks to do its own calculations).
Meanwhile, most kspace solvers use some kind of all-to-all calculation (such as an FFT over meshed charges). So they are penalised more when spread over more processors.
Thus a strategy of having (relatively) fewer processors doing ML short-ranged calculations and more processors doing kspace calculations would seem to combine the worst of both worlds – confining communication-light calculations to fewer procs while spreading communication-heavy calculations over more.
There is no support for “run_style” plugins, but I fail to see why you would need one.
The purpose for using plugins is a matter of distribution of LAMMPS, especially if your code uses libraries or is otherwise incompatible with the GPLv2 library of LAMMPS. For source code, this doesn’t matter. For binaries, those packages/styles must not be included. Using plugins is a workaround, as the linking of the components is done by the individual user and not the distributor.
So for developing your “reversed split” run style, you can just put the .h and .cpp files into the src folder and compile. No other magic needed, if the header complies with requirements using the IntegrateStyle() macro when INTEGRATE_CLASS is defined.
Modifying the source codes is not always possible, especially for the users of supercomputers. It is not so convenient to ask every user to compile a new LAMMPS by themselves. If the plugin mode is available, it will be easier to use a custom module.
I agree with your comments in general. In my cases, however, I use GPU for pair calculation. For the systems of my interest, with hundreds to thousands of atoms, increasing the number of processors would even slow down the inference of ML potentials (probably due to the increasing cost of communication). It is the reason why we do not simply use more processcors. GPU implementation of KSpace does not show too much speedup, neither. I cannot see another straightforward way to go and therefore decided to use the idea of verlet/split.
This is completely contradictory to my experience. On a supercomputer you want to compile HPC applications from source so you can have them optimized as much as possible for your personal needs. I have not come across a supercomputer without compilers. LAMMPS is not a system application, so it does not require any elevated privileges to compile or run.
That user will have to compile a custom LAMMPS executable anyway, if you want to use your custom machine learning packages with Kspace. So where is the harm?
Plugins are highly system specific. They must be compiled with the same compiler, the same settings, the same OS, and the same LAMMPS base source code. You change any of those, the plugin will not load or will cause memory corruption.
You could try enabling the OPENMP package and use multi-threading, ideally with a multi-threaded FFTW3 lib available.
That would also speed up other non-GPU parts of your calculation as far as they are supported by the OPENMP package like fix nvt or building neighbor lists.
To add to @akohlmey comment, it would be very weird for a supercomputer structure to not allow users to compile their own code for specific application. By today’s standard where a lot of different architectures and optimization schemes combinations are possible, that would even make the supercomputer not very useful for new applications, as compilation of most software by the maintainers are generally done with default specifications, not going into the details of who needs what because that would make maintenance impossible.
It is very likely that there is a way to compile LAMMPS from source with different settings and packages as a user. Compilers and other tools (cmake etc.) are often installed through modules you have to load in your environment. If you want to do it yourself, look for the documentation of your supercomputer or get in touche with the administrators.
Yes, I also tried it before. But I found that OPENMP does not help too much for KSpace, neither.
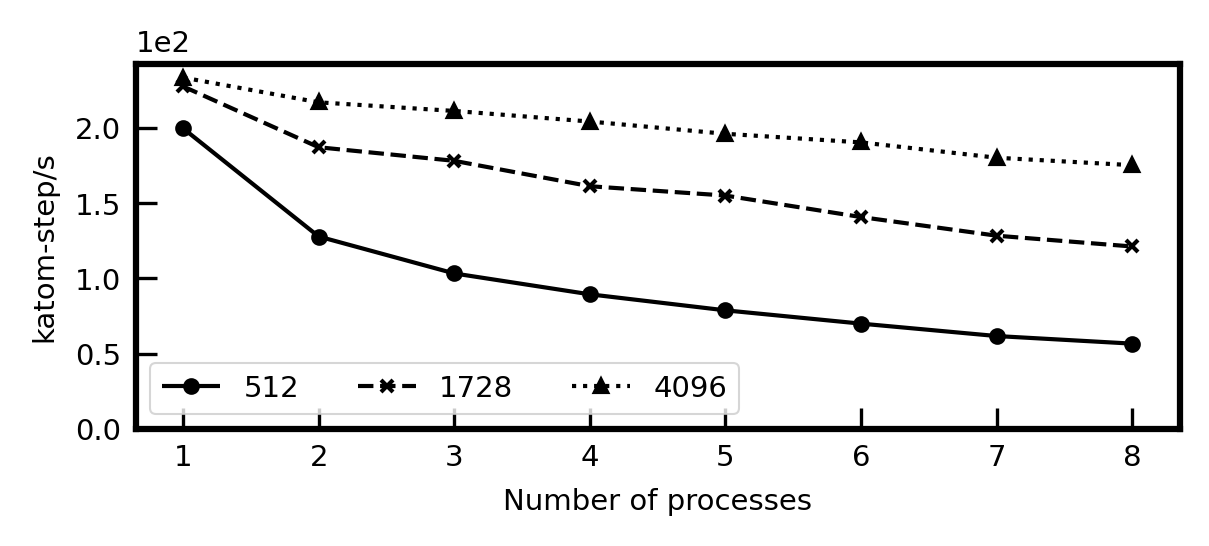
Here is a test case with 512 SPC/E water. The number of threads is 1 for MPI cases, while the number of processes is 1 for OPENMP cases.
I also put the correlation between num. of procs. vs. speed for pair calculation (i.e., ML model inference). In these cases, more procs. will even slow down the simulation.
In brief, in my case: kspace can only be accelerated via MPI, which, unfortunately, will slow down the pair calculation. It is the reason why I turn to the verlet/split algorithm finally.
I apologize for my unclear words.
Indeed the users can compile LAMMPS on supercomputers. What I meant is that the users do not need to compile the whole LAMMPS package by themselves, if the plugin mode is available. Instead, they just need to load the environment for a specific version of LAMMPS (probably provided by the administrators) and compile the plugin package if they want. This helps a lot especially when LAMMPS has complicated dependencies (for some optional packages). For developers, it will be also much easier to test the new module (for different versions).
Yes. The users can compile by themselves on supercomputers. But it is not necessary since there have been some compiled versions that can be used via module load. Plugin modes would make the compiling tasks lighter for the users.
Not really. You are ignoring the requirements for plugins to load cleanly and correctly as I have tried to explain. You need access to the exact same sources and configuration settings and compiler choice etc. or else the plugin does not load correctly.
Plugins are mostly about distribution and that would only matter if you are not planning to submit your code for inclusion into LAMMPS.
That said, I should mention that there are currently some known problems with plugins for certain styles (e.g. kspace_style or run_style) that can only be addressed after we have done a major redesign of how styles are initialized and managed as mentioned in LAMMPS GitHub issue [BUG] Multiple pylammps objects don't work with plugins · Issue #3880 · lammps/lammps · GitHub
Adding code to the plugin package to support run styles is not much work, but it will crash and segfault all the time at the end of each run.
Basically, the plugin management but also the initialization of the maps of factory functions have to become global operation on global data for the LAMMPS executable. Currently, the factory function maps are a per-LAMMPS instance operation and that is inconsistent with the loading of executable code from shared objects in a portable manner.
To prove my point, I just created a feature branch with the option to load run and minimize styles.
UPDATE: While experimenting with some workarounds for the segfault I was mentioning before, I realized a way to refactor the plugin handling without changing how other styles are initialized and thus found a fix for the bug report in issue #3880.