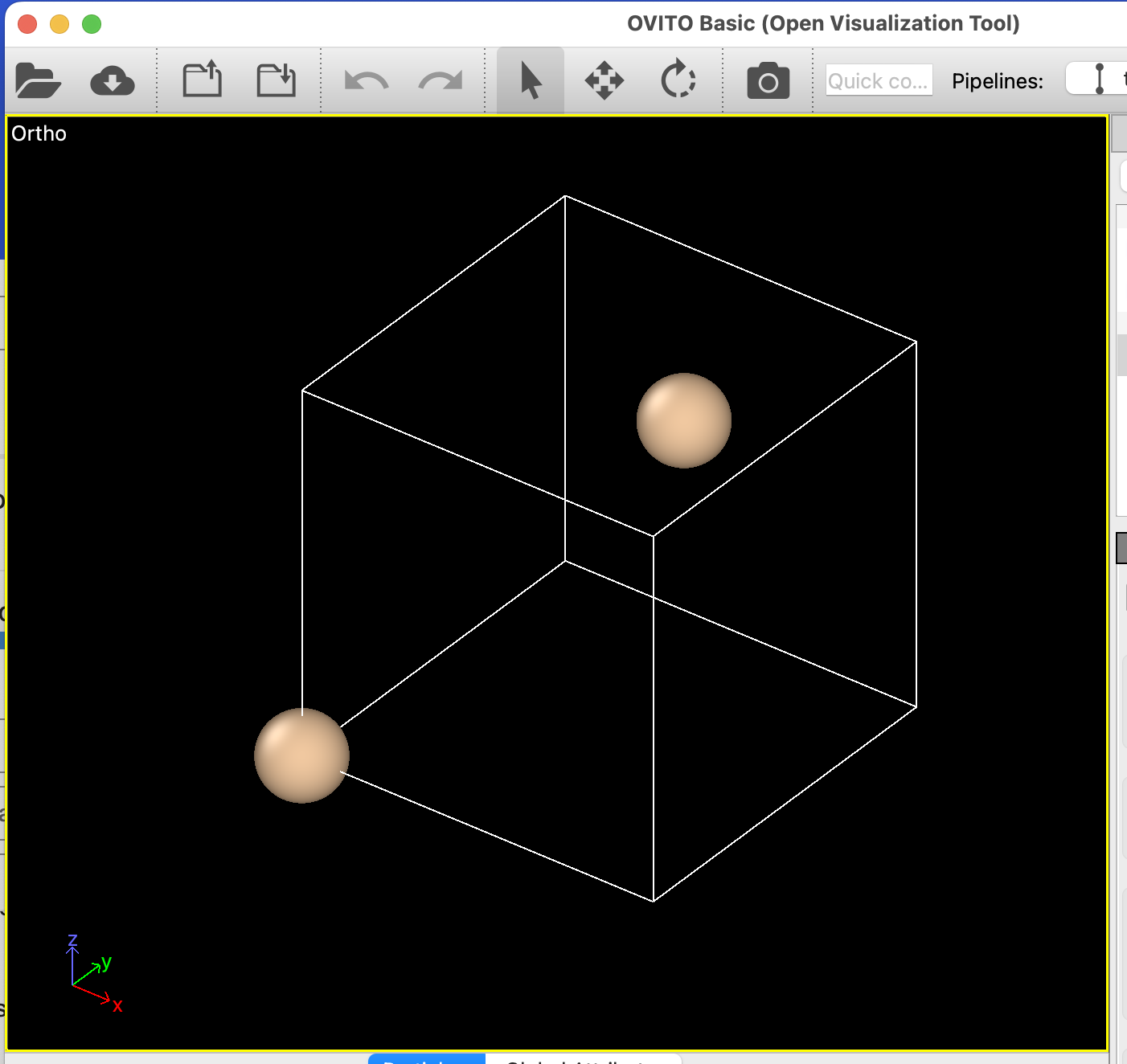
It appears that Ovito assumes that if all the positions in an extxyz file are < 1 that they are in lattice coordinates, even though the Properties=species:S:1:pos:R:3 string indicates that they are Cartesian (I’m not even sure if we came up with an official name for a lattice coordinates field, maybe "scaled_pos" ?. Is this a known issue?
xyz file and screenshot are attached. Atoms should be very close together in a large cell, instead they are not.
example.extxyz (205 Bytes)
Yes, OVITO tries to guess whether the positions in the file are given in reduced coordinates or Cartesian coordinates by checking if they are all in the range 0-1. You can override this behavior by turning off the option “Detect reduced coordinates” in the GUI:

Then OVITO will assume Cartesian coordinates even if they are all inside the unit cube. This should solve your problem.
It is a valid question how to distinguish the type of coordinates with certainty. The extended XYZ format is not standardized or officially specified at all. Historically, there have unfortunately been different interpretations and variants of the file format written by simulation codes or other software tools, which always used the same column identifier “pos” - for both reduced and Cartesian coordinates.
On OVITO’s side, we could think about turning off the “Detect reduced coordinates” option by default if XYZ files using reduced coordinates have become very rare nowadays and XYZ files containing small Cartesian coordinates, like in your case, more frequent.
Thanks. As the developers of extxyz it was our intent that "pos" definitely be Cartesian, and another tag would be required (not sure if we ever settled on one) for lattice positions. FWIW, there is a more formally specified definition which is basically developed, but we haven’t quite gotten over the finish line on the new parsers.
Sorry, I hadn’t realised that you are professionally involved with the XYZ file format and are part of a project trying to formally specify the extended format. This is the first time I’ve come across the extxyz project.
So your question is probably less about a personal problem that needs to be solved, but you are interested in generally improving the data exchange between different codes, including OVITO.
We OVITO developers will take a closer look at the extxyz specification you are building. The heuristics for detecting reduced coordinates in OVITO are independent from the extended XYZ format or the presence of the “pos” data column. The detection kicks in whenever cell dimensions were found in the file. But that cell info can also stem from other dialects of the XYZ format, e.g. OpenBabel exyz or some historical MD formats, which are likely no longer in active use today.
If you say that extended XYZ does not allow for reduced coordinates under any circumstances, at least not in the “pos” column, then it would actually make sense to skip the autodetection in OVITO completely in this case, yes.
I was the original contributor of the extended XYZ support in OVITO. Just to follow up on what @noam.bernstein has said, pos was never intended to store fractional coordinates in extended XYZ files. frac_pos has been used for this, but this is not part of the standard.
As well as a formalised specification, the extxyz repo also includes a reference pure C extxyz parser which we would be very happy for you to use in Ovito if it fits in. This would help to ensure consistent behaviour between different codes and frameworks. If you prefer to write your own parser based on this spec, then there are BNF and Lark grammars based on it at https://github.com/Luthaf/extended-xyz/tree/master/exyz-lark
I see, thanks again for the clarification. Our current plan is to turn off the auto-detection of reduced coordinates (solely based on the value range) for extended XYZ files in the future to prevent the kind of problem reported by @noam.bernstein. Of course, it would still be possible to automatically do the conversion to Cartesian coordinates in case the file column is named “frac_pos” instead of “pos”.
I took a quick look at the libextxyz C library. Its integration into OVITO may not be possible due to the current API design. Mainly for three reasons:
- OVITO’s file parsers do not use C file objects (
FILE*) but the cross-platform Qt framework. This enables parsing data from any type of source, e.g. SSH or https network streams, in-memory buffers and compressed XYZ files.
- all I/O operations must be cancellable by the application at any time. This is important for interactive functionality in a GUI environment, because the user may interrupt the loading of a frame. Random access to all frames of a trajectory is also important.
- OVITO’s current parser for XYZ files is highly optimised and uses the Boost Spirit-qi framework for string-to-number conversion. It offers routines that are faster than C functions such as
atof().
Of course, I can see the advantage that libextxyz could offer, as it could immediately provide fully standards-compliant behaviour. However, its programming interface would have to be adapted for an integration in OVITO. In addition to a single high-level function that reads an entire “Atoms” object from a FILE* stream, there should also be low-level functions that, for example, only parse the xyz comment line or individual lines of atoms data, one at a time. These low-level functions should accept C-strings as input instead of a file object. Then we could use them in OVITO, I think.
Let me know what you think. Honestly, I’m not sure which way is best. We already have a well working parser for XYZ files in OVITO, and we could try to improve its standard conformance instead of exchanging the whole underlying system. If we do this, then a test suite of XYZ files might be helpful to verify compliance.