Hello everyone,
In this opportunity I would like want to expose a few questions that I got when trying to understand well the benchmark method in automatminer, and the retrieved “predicted_folds” list and the “best_models” dictionary.
For instance (as a case of study), I’m running a benchmark (debug preset, kfold=5). At the end I use the obtained predictions of the predicted_folds to calculated rmse’s for each fold:
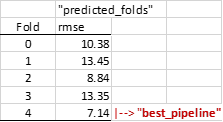
pipe.learner.best_pipeline:
Pipeline(memory=Memory(location=/tmp/tmpwgh7yz9_/joblib),
steps=[(‘selectpercentile’, SelectPercentile(percentile=57,…)
(‘maxabsscaler’, MaxAbsScaler(copy=True)),
(‘extratreesregressor’,…)
I understand that the “best_pipeline” corresponds to the “global best pipeline” which is the one that provides the lowest test fold error. In this example the “best_pipeline”, is therefore a pipeline identified during fold[4].
Here my first question, the predictions of the other folds (0, 1, 2, 3), are obtained applying other “local best pipelines”, obtained in the corresponding fold[n]? If so, then those “local best pipelines” might use different ML-algorithms (not necessarily etr, but others). In that case, it makes no sense to average the errors of the five folds, because each fold error, is calculated using a different pipeline.
My second question is related to the dictionary obtained in “pipe.learner.best_models”. In the present example,
pipe.learner.best_models:
OrderedDict([(‘ExtraTreesRegressor’, -6.724502205567023),
(‘RandomForestRegressor’, -6.959273286928392),
(‘DecisionTreeRegressor’, -7.233240134394501),
(‘ElasticNetCV’, -7.334800528561516),
(‘LassoLarsCV’, -7.429971666602927),
(‘GradientBoostingRegressor’, -7.568739134833447)])
According to this dictionary the “greater_score_is_better” (in this case, ExtraTreesRegressor (etr) is the best model). This agrees with the fact that the best_pipeline also involves etr as the ML-algorithm.
My question is, how are the “pipe.learner.best_models” scores obtained? Are they accumulated during autoML (in the internal loop of each fold), or they are cumulative scores obtained during the prediction step at the end of each fold (in the outer loop)?
Is it correct to use these scores to make comparisons between different pipelines (e.g. obtained with other presets? –>“greater_score_is_better”)
I have these doubts, because I’ve noticed that after the fitting of MatPipe (at the end of each fold), the consecutive prediction is very fast, and I was wondering, if only “the best local pipeline” is being used for predictions, or if several “best local pipelines” (one for each ML-algorithm) are tested, and the averaged or unified score is finally stored in “best_models”.
Below you can see a scheme I’ve prepared, to illustrate what “I understand” is happening during benchmark method in automatminer:
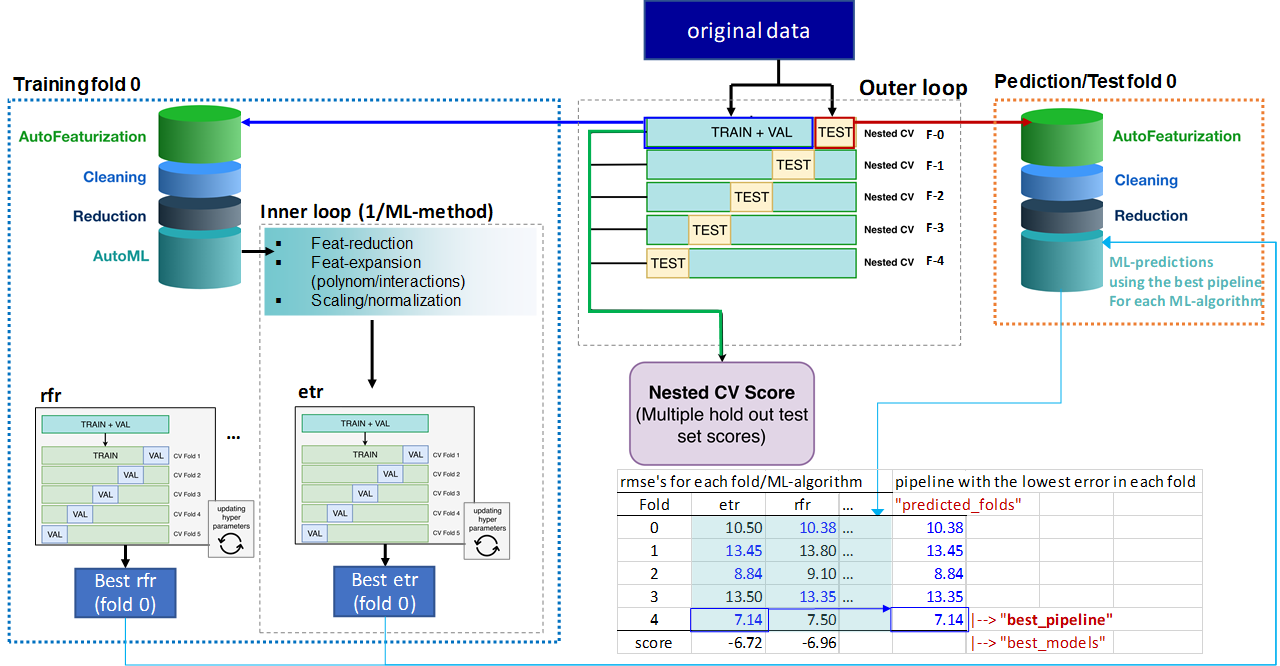
I would really appreciate any clarification/correction of what I’m presenting here. I’ve been struggling in collecting information from the documentation of automatminer/TPOT but haven’t managed to locate these details.
Regards,
Jorge