Hi All,
I used the Benchmarking Lammps examples to compare the performance of my machine ( AMD Ryzen Threadripper 3970X 32-Core, 64-Thread) with the given benchmarks. I have the following questions about how the performance is versus the number of cores used and would appreciate it if you could share your thought on this. A quick note that I have turned off the “Simultaneous Threading” (Intel’s Hyperthreading) option on the Bios.
-
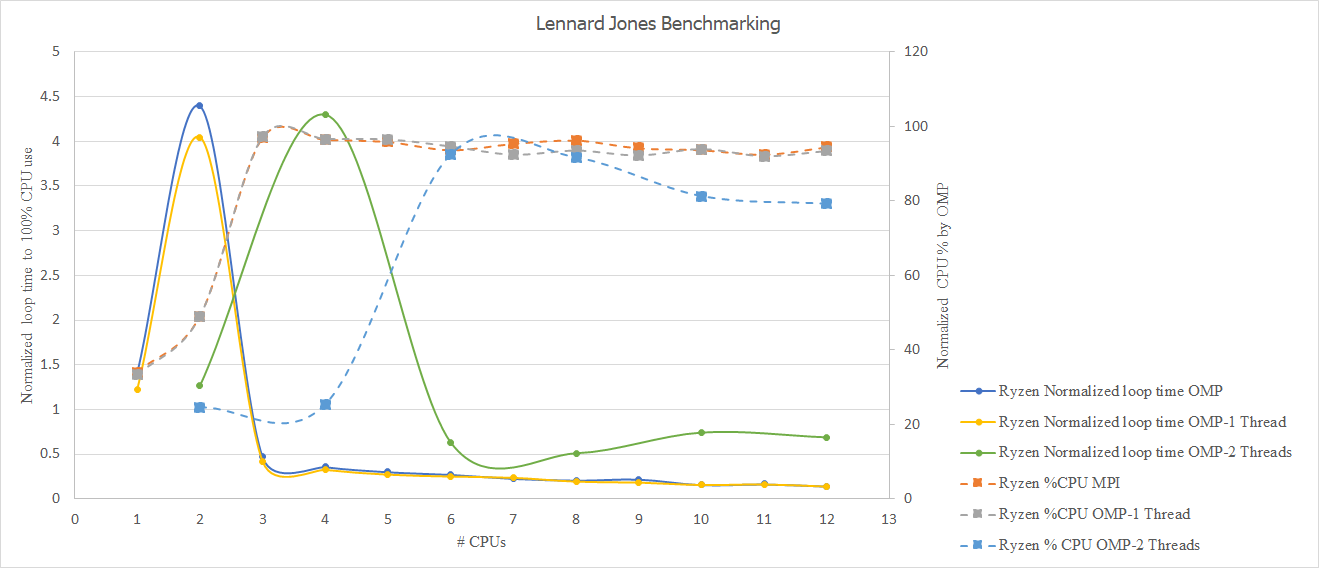
Why is the loop time of 2 cores using MPI and OMP (1 -thread per cpu) and 4 cores using OMP (2 Threads per cpu) is the lowest? There seems to be a correlation between the number of threads used and the minimum performance-number of cores.
-
Why is the % CPU used so low for 1 and 2 cores (2 and 4 processors in the case of OMP using 2 threads) used?
Best regards,
Amir Behbahanian
Mechanical & Aerospace Engineering
Utah State University
4110 Old Main Hill
Logan, Utah 84322
[email protected]
It is difficult to comment on these things without knowing more details about how you compiled and run LAMMPS. Also your numbers are tricky to interpret and I don’t understand exactly what you are mean by “normalized”.
It would be better if you report:
- LAMMPS version used
- Compiler type and version
- MPI library and version
- Compiler flags
- Command lines
- System size
- Processor affinity related settings (and MPI library defaults!) and environment variables
For reliable benchmark numbers you should be running on a machine that you have exclusive access to and where there is nothing else running on. So LAMMPS should always report 100% or close to 100% CPU utilization for MPI-only and similarly higher values for OpenMP threads (but since not the entire code is run with active threads, you will not reach N_threads * 100%).
You also should note that CPU utilization is not a good measure for parallel efficiency. You can have high utilization (e.g. through busy looping) and still low parallel efficiency. So only absolute times matter.
Finally, depending on the system size, there is a limit for strong scaling, i.e. the ability to run faster with more CPUs used.
Thank you so much for your reply. The left y-axis would be the loop time if I were able to get 100% CPU use (e.g., loop time for q MPI CPU use is 4.12 sec. and the % CPU use is 34; thus, I reported 1.4 sec as the normalized bu %cpu for the first data point on the blue solid line). Also, with %CPU, which is reported on the right y-axis, I divided the number by the number of threads used to get a value below 100. Please find the system properties the following:
-
LAMMPS version: LAMMPS (27 May 2021)
-
Compiler Type and version: gcc (GCC) 9.3.1 20200408 (Red Hat 9.3.1-2)
-
MPI library and version: mpirun (Open MPI) 4.1.1
-
Compiler flags:
* MPI: original mpi make file flags
* OMP: -Wrestrict -fopenmp
-
Command lines and System size: no x y z was passed through by the run command
variable x index 1
variable y index 1
variable z index 1
variable xx equal 20*$x
variable yy equal 20*$y
variable zz equal 20*$z
units lj
atom_style atomic
lattice fcc 0.8442
region box block 0 {xx} 0 {yy} 0 ${zz}
create_box 1 box
create_atoms 1 box
mass 1 1.0
velocity all create 1.44 87287 loop geom
pair_style lj/cut 2.5
pair_coeff 1 1 1.0 1.0 2.5
neighbor 0.3 bin
neigh_modify delay 0 every 20 check no
fix 1 all nve
run 100
- Processor affinity related settings (and MPI library defaults!) and environment variables: I have the conda environment activated by default, and a couple of security protocols are also running in the back ground. Other than those, the system is solely used for LAMMPS.
Best regards,
Amir
The default settings for the LJ benchmark will create a system with only 32000 atoms, which will run in sub-second time for the 100 steps. This is far to short to get any meaningful benchmark numbers.
With modern CPUs, timing is not very reliable due to the effects of Turbo-Boost and similar CPU and chipset features that can dynamically change the performance.
If nothing else is running on your machine, then you should be getting near 100% CPU utilization with MPI-only runs. Here are some examples from my machine with the following compilation settings
OS: Linux "Fedora 33 (Thirty Three)" 5.13.4-100.fc33.x86_64 on x86_64
Compiler: Clang C++ Clang 11.0.0 (Fedora 11.0.0-3.fc33) with OpenMP 5.0
C++ standard: C++11
MPI v3.1: Open MPI v4.0.5, package: Open MPI [email protected] Distribution, ident: 4.0.5, repo rev: v4.0.5, Aug 26, 2020
CXXFLAGS = -O2 -g -DNDEBUG
CPU = Intel(R) Core(TM) i7-7700 CPU @ 3.60GHz Quad-core
mpirun -np 1 ./lmp -in ../bench/in.lj
Loop time of 1.27009 on 1 procs for 100 steps with 32000 atoms
Performance: 34013.232 tau/day, 78.734 timesteps/s
99.8% CPU use with 1 MPI tasks x 1 OpenMP threads
=================
mpirun -np 2 ./lmp -in ../bench/in.lj
Loop time of 0.690559 on 2 procs for 100 steps with 32000 atoms
Performance: 62558.059 tau/day, 144.810 timesteps/s
98.7% CPU use with 2 MPI tasks x 1 OpenMP threads
=================
mpirun -np 4 ./lmp -in ../bench/in.lj
Loop time of 0.371563 on 4 procs for 100 steps with 32000 atoms
Performance: 116265.680 tau/day, 269.134 timesteps/s
98.2% CPU use with 4 MPI tasks x 1 OpenMP threads
Please note that OpenMPI will by default bind MPI processes to individual cores, so that would need to be changed when using OpenMP:
mpirun -np 1 -x OMP_NUM_THREADS=1 ./lmp -in ../bench/in.lj -sf omp
Loop time of 1.09566 on 1 procs for 100 steps with 32000 atoms
Performance: 39428.190 tau/day, 91.269 timesteps/s
99.7% CPU use with 1 MPI tasks x 1 OpenMP threads
=================
mpirun -np 1 -x OMP_NUM_THREADS=2 ./lmp -in ../bench/in.lj -sf omp
Loop time of 1.1228 on 2 procs for 100 steps with 32000 atoms
Performance: 38475.168 tau/day, 89.063 timesteps/s
98.5% CPU use with 1 MPI tasks x 2 OpenMP threads
=================
mpirun -np 1 --bind-to socket -x OMP_NUM_THREADS=2 ./lmp -in ../bench/in.lj -sf omp
Loop time of 0.5705 on 2 procs for 100 steps with 32000 atoms
Performance: 75722.992 tau/day, 175.285 timesteps/s
199.6% CPU use with 1 MPI tasks x 2 OpenMP threads