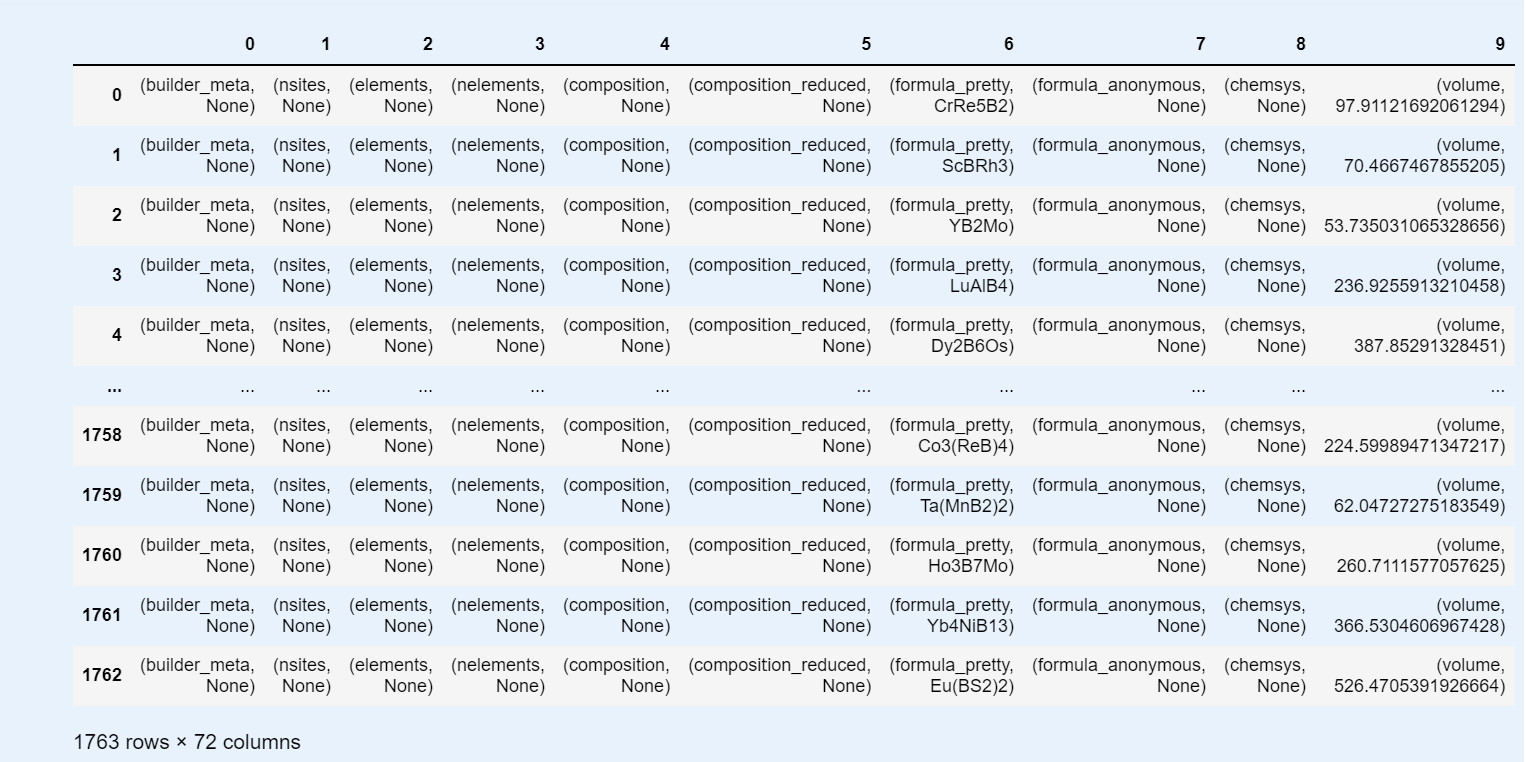
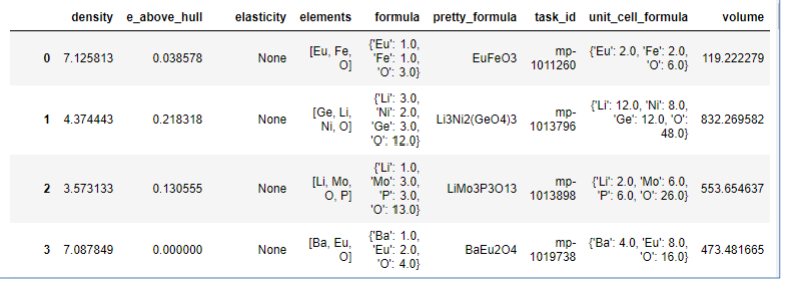
I am trying to convert the resulting query into a pandas dataframe as shown below, but format of the resulting dataframe looks off with the field name for fields I queried being in the tuples on each row instead of a being the title for each column Is there a simple way to get a dataframe like the last picture I have attached programmatically?
here’s one way to go about it. It probably isn’t the most efficient and @munrojm might have better suggestions.
from flatten_dict import flatten
flattened = [{
k: v for k, v in flatten(doc.dict(), reducer="dot").items() if k != "fields_not_requested"
} for doc in docs]
DataFrame.from_records(flattened)
I am having the exact same issue. I have tried a variety of pandas methods (str.replace, str.rstrip, str.lstrip lambda: x, …) but they completely take out all data in that column (resulting in NaN), including the numerical values I want. I’m wondering if this isn’t working because the data in the columns aren’t strings?
@kikin you’re trying to flatten a Dataframe whereas flatten takes a dictionary. Loop over the results from mpr.summary.search (docs in my example) and not the rows of a dataframe.
Thanks for the useful code snippet!
I usually save the query results to a csv file and in that case I add the following line before exporting to csv. This makes it easier to load the structures later with Structure.from_dict or Structure.from_str.
fields = [
"material_id", "band_gap", "volume", 'formula_pretty', 'is_stable',
'spacegroup'
]
with MPRester(apiid) as mpr:
docs = mpr.materials.summary.search(chemsys="Si-O",
band_gap=(0, 10),
fields=fields)
flattened = [{
k: v
for k, v in flatten(doc.dict(), reducer="dot").items()
if k != "fields_not_requested"
} for doc in docs]
df = pd.DataFrame.from_records(flattened)
df = df.drop(columns=[col for col in df if col not in fields])
But, IMHO, the problem can be easily solved if upstream considers not to write fileds_not_requested every time.