Hello,
I’m planning to study the pressure dependence of heat transfer in a graphene–water system. For computational efficiency, To generate different confining pressures of water I’d like to run simulations on a single replica and then create a mirror-symmetric copy, rather than simulating a larger system with fully distinct particle types.
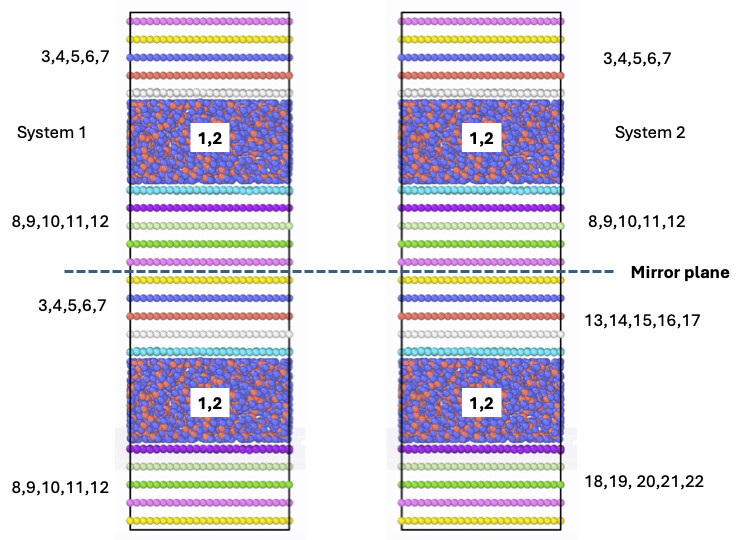
I’m comparing the energy minimization of two graphene–water systems:
- System 1: Graphene is modeled with 12 particle types (e.g., types 3–7 and 8–12 for graphene) and water as types 1–2.
- System 2: Each graphene sheet is assigned a unique type (totaling 22 types) while water remains as types 1–2.
Both use identical interaction rules (Tersoff within graphene; LJ between graphene sheets and between graphene and water, with the same cutoff). Before minimization, the energies match exactly. However, after energy minimization, System 1 reaches an energy of about –76,717 eV, whereas System 2 minimizes to about –76,705 eV. Also, the minimization requires different number of steps to attain convergence in systems 1 and 2.
Why might the minimized energies differ despite the same starting energy and identical interaction parameters? Could this be due to numerical round-off differences, or convergence to different local minima because of the extra particle type distinctions?
My LAMMPS version is 29Aug2024. Any insights would be appreciated.
I’ve attached a snapshot of the system I’m dealing with.
Thanks in advance.