Dear experts,
I’m trying to generate polariztaion workflows with the following codes:
import numpy as np
from pymatgen.core.structure import Structure
from fireworks import LaunchPad
polar = Structure.from_file(‘BTO_polar_POSCAR’)
nonpolar = Structure.from_file(‘BTO_nonpolar_POSCAR’)
wf = get_wf_ferroelectric(add_analysis_task=True,polar_structure=polar, nonpolar_structure=nonpolar, nimages=2,relax=True,vasp_cmd=“mpirun -np 24 /TGM/Apps/VASP/bin/5.4.4/O3/NORMAL/vasp.5.4.4.pl2.O3.NORMAL.std.x”)
lpad = LaunchPad.auto_load()
lpad.add_wf(wf)
Later qlaunch rapidfire, my calculations were FIZZLED in the last step, like this:
{
“state”: “FIZZLED”,
“name”: “unnamed WF–1”,
“created_on”: “2022-06-14T04:44:04.209000”,
“states_list”: “F-C-C-C-C-C”
}
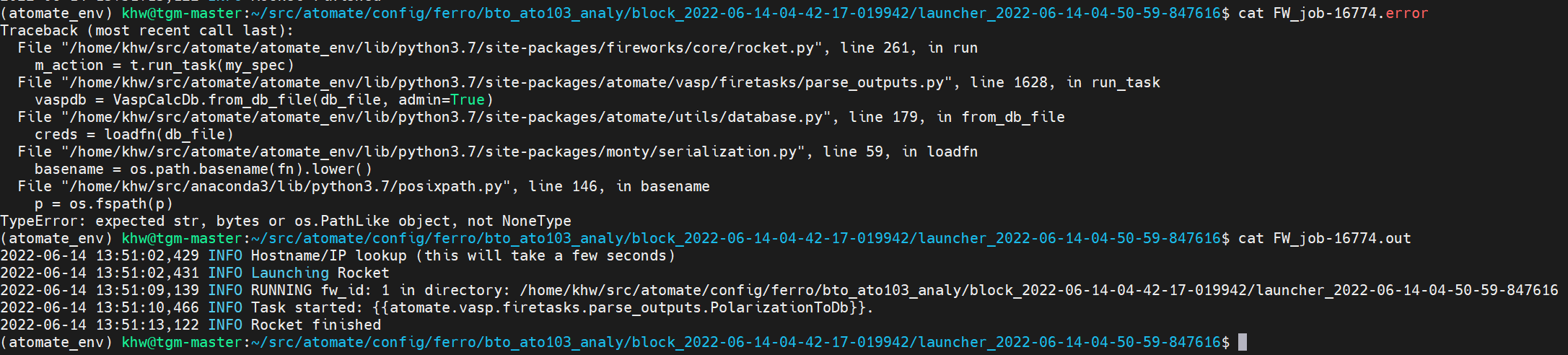
I checked ‘FW_job.error’ and FW_job.out’ in the error directory as follows:
However, I can’t solve it, so I ask the experts.
How can i fix this problem?
Hi Hyeon
it seems that the PolarizationToDB task cannot upload the results into the DB.
Have you specified a database/collection to store the results? This should be written in
a db.json file which is part of the Atomate configuration.
Hi, Ricci!
Based on your thankful feedback, I added the ‘db_file’ tag to my workflow code like this:
wf = get_wf_ferroelectric(db_file=‘/home/khw/src/atomate/config/db.json’,polar_structure=polar, nonpolar_structure=nonpolar, add_analysis_task=True,nimages=2, vasp_cmd=“mpirun -np 24 /TGM/Apps/VASP/bin/6.2.0/O3/AVX2/vasp.6.2.0.O3.AVX2.std.x”, relax=True,wfid=‘1’,tags=[‘AlN’])
And I relaunch workflows.
However, it was FIZZLED again at same stage with different error message as follows:
Here, could you please let me know if there are any other ways?
I finally fixed this problem by removing the ‘wfid’, ‘tags’ tags and replacing the ‘nimages=10’ in my workflow code.
I got successful results in MongoDB.
Thanks you so much!
1 Like
Great! Yes, it’s better to let the workflow decide the wfid. I think that’s likely the reason why it got stuck the second time. Also, it is better to have at least 10 interpolated branches to correctly find the right polarization branch. Lastly, as you can see now that you are passing a db.json you got a polarization_tasks collection with all the important output from the calculation performed by the workflow. Basically, you can do most of the analysis scraping from that collection.
Have fun!
1 Like