Hello,
According to NVIDIA, the nominal performance of HNS benchmark using 8 x A100-SMX4 is 2.44E+07 ATOM-Time Steps/s. (https://developer.nvidia.com/hpc-application-performance)
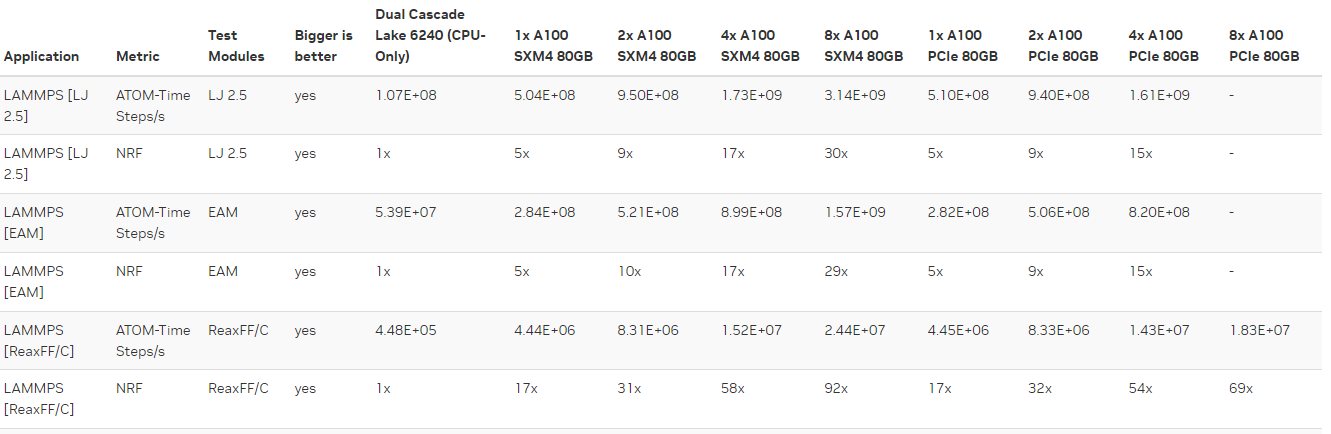
I was able to replicate this result using NGC containers, as follow:
mpirun \
-np 8 \
singularity \
run \
--nv
./lammps_4May2022.sif \
/usr/local/lammps/sm80/bin/lmp \
-k on g 8 \
-sf kk \
-pk kokkos cuda/aware on neigh half comm device neigh/qeq full newton on \
-var x 16 \
-var y 16\
-var z 16 \
-var steps 1000 \
-nocite \
-in in.reaxc.hns \
-log reacx-ngc.log
resulting in 2.66E+07 ATOM-Time Step/s, which could be attributed to usage of a different host CPU.
Then, I am trying to replicate this result with LAMMPS package built via Spack (0.19.1)
spack install lammps@20220504 %[email protected] target=zen3 +kspace +manybody +molecule +opt +openmp-package +openmp +reaxff +kokkos ^[email protected] +aggressive_vectorization +cuda cuda_arch=80 +cuda_lambda +cuda_ldg_intrinsic +cuda_uvm +wrapper
Here, Kokkos 3.7 was built with CUDA backend and addition functions such as UVM.
Other dependencies such as OpenMPI and UCX were also built as CUDA-awared libraries (+cuda)
^[email protected]%[email protected]~atomics+cuda~cxx~cxx_exceptions~gpfs~internal-hwloc~java+legacylaunchers~lustre~memchecker+romio+rsh~singularity+static+vt+wrapper-rpath build_system=autotools cuda_arch=none fabrics=ucx schedulers=none arch=linux-centos7-zen3
^[email protected]%[email protected]~assertions~backtrace_detail~cma+cuda+dc~debug~dm+examples~gdrcopy~ib_hw_tm~java+knem~logging~mlx5_dv+openmp+optimizations~parameter_checking+pic+rc~rdmacm~rocm+thread_multiple~ucg~ud~verbs~vfs~xpmem build_system=autotools cuda_arch=none libs=shared,static opt=3 patches=32fce32 simd=auto arch=linux-centos7-zen3
The command to run the benchmark was same as in NGC case.
mpirun \
-np 8 \
lmp \
-k on g 8 \
-sf kk \
-pk kokkos cuda/aware on neigh half comm device neigh/qeq full newton on \
-var x 16 \
-var y 16 \
-var z 16 \
-var steps 1000 \
-nocite \
-in in.reaxc.hns \
-log reacx-spack.log
This time, I obtained only 1.74E+7 ATOM-Time Step/s.
Since I am not yet allowed to upload file, here are links to the two outputs files:
reax-ngc.log
reacx-spack.log
Kokkos is open source and I don’t think NVIDIA has made addition optimizations to create such large performance gap. Any insights and suggestions are much appreciated.
Regards.