I modified that preset my-kokkos-sycl-intel.cmake to include the settings that generate AOT kernel compiles. I also turned off OpenMP because it’s nothing but trouble.
It turns out that cmake file I uploaded is no good. The hardcoded values for MPI are not correct, so no parallel is possible. Annoyingly, instead of complaining about it, cmake just defaulted to the builtin MPI stubs. After I commented out the line for MPI executable and instead turned on BUILD_MPI to encourage cmake to find MPI on its own, cmake was actually able to find and use it.
In addition to the variables @stamoor suggested (Jan 4), I also needed to do unset ZE_AFFINITY_MASK. For some reason, the latest Intel MPI refuses to do gpu/aware when that variable is set.
After rebuilding and setting all these annoying variables, I can now fully parallelize across multiple PVC GPUs. Even the kspace for Rhodopsin benchmark is working correctly. This is very exciting indeed.
I put my build in a container. If someone you know has PVCs and would like to try my build, I can share it.
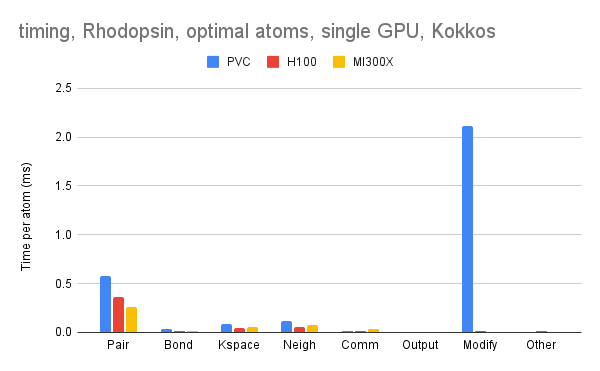
I have done enough benchmarks to find the next major problem.
The modify time is way too high. Additional PVC gpus don’t add much performance either. I suspect that one of the fix commands is being done on the CPU or something like that.
Hmmmm, the profile on GPU looks fine. Maybe a little initialization overhead that we could get rid of, but otherwise very reasonable. So that means the overhead is on the host CPU, which kokkos-tools won’t pick up. So you need to profile the host CPU. I typically use gprof by compiling with -pg but maybe there is a better tool for Intel, not sure.