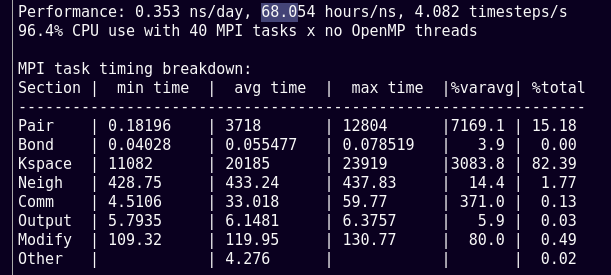
Hi Lammps users, I"ve been working on a droplet of water on silica. The system has around 120.000 atoms, but the perfomance is around 68 [hrs/ns] with 40 processors MPI (lower than the spected). I would like to know if someone can help me with some function of LAMMPS or modify any parameter to speed up the simulation. As you can see in the performance chart, the kspace is carrying the most of the computational cost.
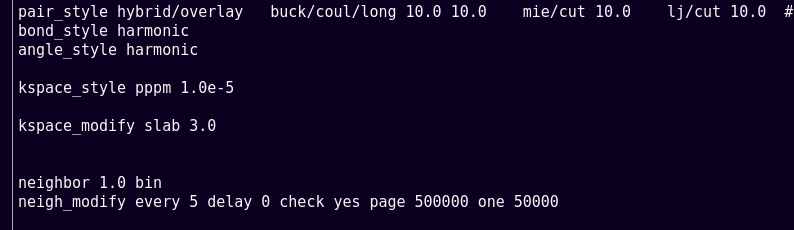
I"m using hybrid pair style, as you can see in the picture above.
I tried to speed it with the slab modify due to the context of the problem, and the simulation box only has 4 [nm] of vacuum for Z+ and Z-, the other directions are periodic. And it speeds up from 170 [hrs/ns] to 68 [hrs/ns], but as I said, I think is too slow for a small system.
Here is image context of the simulation.
Thanks!.
Have you try different number of processors? 40 processors seems like a lot for small systems. Its not “the more processors the better” as you have to account for the communication time. In addition, your systems has a lot of vacuum, so you may want to try to use fix_balance to better balance computational load across processors.
Best,
Simon
Without your input file or full output it is difficult to give specific advice, but notice how there is a very large spread between min and max times spent on Pair and KSpace – this suggests that some MPI ranks have almost no particles assigned to them and get through their force calculations quickly, while other MPI ranks have far more particles assigned. This will be a big hindrance to parallel performance.
Furthermore, kspace_modify slab is not a way to speed up (or slow down) a simulation – it is a completely different physical model of the system.
Some general points:
On a HPC, make sure you’re avoiding communication between nodes as much as possible. Whether on one node or many, make sure you’re requesting exclusive access and specify the right number of MPI procs to fill them up.
Use the OPENMP package to reduce MPI communication by having half the number of MPI procs and running two OpenMP threads per proc.
Run a short benchmark on a small number of procs, say half an hour on 2 procs. If you’re spending about 1.5-2x as many core-hour per ns scaling up to 40 procs, that’s okay! It’s completely possible that this is just the speed you should expect.
Partition the processors intelligently with the processors command – either processors * * 1 or (with careful consideration of the z cutoff point) processors * * 2 may significantly speed up your run.
Try increasing the Coulombic short range cutoff (carefully). Roughly speaking, pair comms are neighbour (proc) to neighbour and KSpace comms are all to all. Increasing the Coulombic cutoff shifts computational work from KSpace to pair, which may be better for comms on large numbers of procs. I don’t remember offhand if fix tune/kspace works with hybrid pair styles, but if it does you should try it.
Thanks for your replies, I tried the 4th general point and the time drops from 68 to 30 [hrs/ns], with processors * * 1. The energies change a little, but less than 5%.