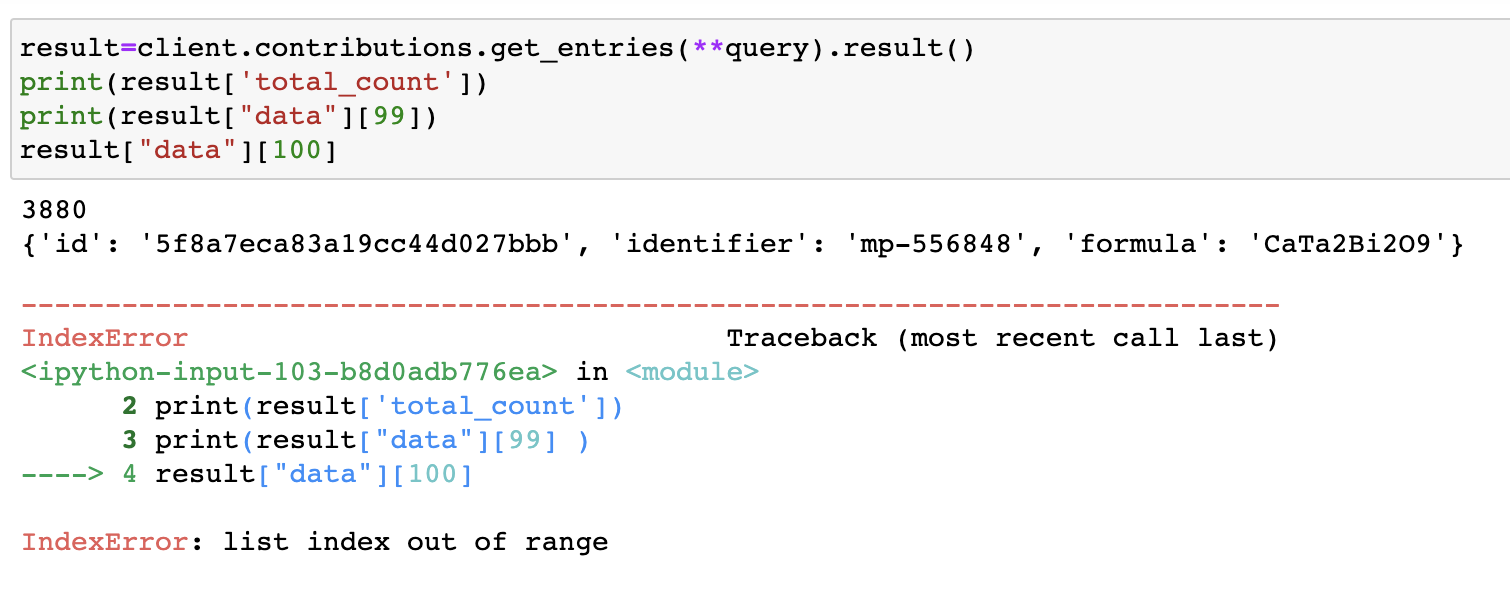
I want to obtain a list of all materials satisfying my query. My current query results in 3880 materials, however I can only access a maximum of 100 of them regardless of what the query is. I would love it if someone could point me to what my issue could be.
I appreciate your time and consideration,
Daniel
Hi Daniel,
the responses from the MPContribs API are paginated and by default it returns your first 100 results. To loop through all the entries satisfying your query you can increase the per-page limit using the _limit or per_page parameters up to 500, and check the has_more field in the response to increment the page number as long as there are more results to return. However, as you already did, before you start looping through a potentially long list of results, you’ll want to tune the query to return a reasonable subset of contributions. Sometimes the first page (and a small per_page parameter) might be enough if descending or ascending order based on a field is requested via _sort. It’s also important to use the _fields parameter to only include the fields you need in the response. Below is an example for the carrier_transport dataset.
from mpcontribs.client import Client
query = {
"project": "carrier_transport",
"formula__contains": "Au",
"data__PF__p__value__lt": 10,
"data__PF__n__value__gt": 1,
"_sort": "-data.S.n.value", # descending order
"_limit": 170, # up to maximum 500 per request
"_fields": [
"identifier", "formula", "data.metal",
"data.S.n.value", "data.S.p.value",
"data.PF.n.value", "data.PF.p.value"
],
}
contributions = []
has_more, page = True, 1
with Client() as client:
while has_more:
resp = client.contributions.get_entries(
page=page, **query
).result()
contributions += resp["data"]
has_more = resp["has_more"]
page += 1
len(contributions)
HTH
thanks,
Patrick
Just wanted to update this thread with latest examples for retrieving MPContribs datasets. Pagination is now automatically handled by the client (make sure to update to the latest version of mpcontribs-client) and configuration parameters are easier to set using the client.query_contributions() function. The client can also be initialized with a specific project. The previous example becomes
from mpcontribs.client import Client
client = Client(apikey="your-api-key-here", project="carrier_transport")
client.available_query_params() # print list of available query parameters
query = {"formula__contains": "Au", "data__PF__p__value__lt": 10}
fields = ["identifier", "formula", "data.metal", "data.S.n.value"]
client.query_contributions(
query=query, fields=fields, sort="-data.S.n.value", paginate=True
)
By default, paginate is False which will only retrieve the first page of results and should be used to test the query, fields and sort parameters before paginating through all results.
If entire projects or large subsets of contributed data are downloaded for later used, it is often more efficient to use the client.download_contributions() function. It also takes a query as argument and downloads all results as json.gz files behind the scenes. Only locally missing data is downloaded when download_contributions is run and contributions are loaded from disk. This function always retrieves all fields included in the data component, so the fields argument is not available/needed. Additional components (i.e. structures, tables, and attachments) can be included in the downloads through the include argument:
client.download_contributions(query=query, include=["tables"])