Dear Axel,
Thank you very much for replying my email. I'm sorry for keeping bothering
you with this *simple* question which perhaps looks straightforward for you
(and others), and I did read all the mailinglist questions regarding
'ave/correlate' but unfortunately still didn't get there. I admit that it
is my fault of not organizing my questions correctly and properly, but I
will try then.
- Nevery determines the spacing of the nrepeat samples of data being used
(i.e. 1 is every step) Yes I know.
The question comes to Nrepeat and Nfreq. My understanding is: you take the
data every Nfreq, and calculate the autocorrelation function out of this
Nfreq data, wherein the output autocorrelation function is C(deltaTime),
and deltaTime = multiple of Nrepeat. So you get different ACF every Nfreq,
and each Nfreq ACF (let's call it as ACF(Nfreq=j)) can be different. If
that right?
this depends on the specific settings and particularly the "ave" mode
selected. i must repeat: read the documentation! it is all there, you seem
to be skipping over details. but more importantly, you seem to be reading
it with pre-conceived notions of what is happening that are incorrect.
the nfreq data samples are *only* collected on the nrepeats steps before
and including the nfreq steps.
I did try out running my simulation in with different parameters but they
don't actually correspond to what I would expect from the scripts, and I
don't really understand why people would like to set the Nfreq small since
it gives bad statistics (if I understand correctly). If you don't might -
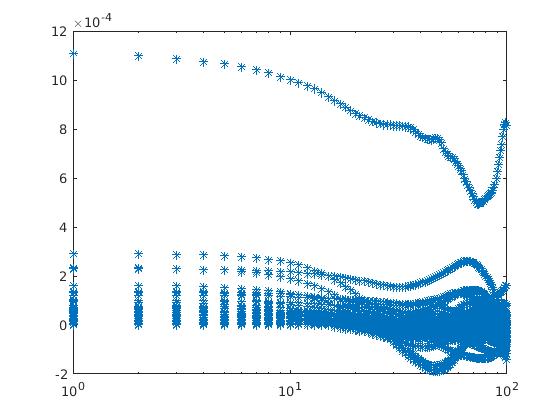
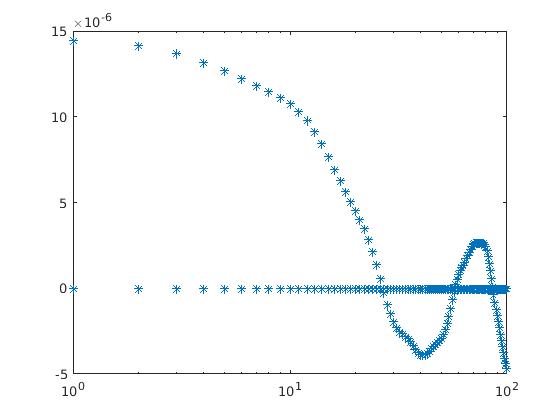
here I attached two figures for different choices of Nfreq: let one with
Nfreq = Nrepeat, and the right one with Nfreq=total running step. x-axis
stands for the time series and y-axis stands for the out put ACF.
this is not what i recommended you to do and also seems to indicate, that
you have no good understanding of the statistical noise and convergence of
the property you are sampling and auto-correlation functions in general.
most of the data your are plotting is pointless to look at, as it is
clearly just unconverged noise. as before, we are now getting to a point
again, where you should obtain proper consulting and training from your
adviser/supervisor. it is becoming increasingly obvious that your progress
is hindered particularly by your lack of training. i have to repeat, that
this mailing list is not classroom and we have no time to teach everybody
personally what they should have learned *before* doing simulations on
their own and without supervision.
Sorry for bothering so much but I will think twice (or twice twice)
before I ask the next question!
BTW: these plots are useless without knowing what you are actually
auto-correlating.
at any rate, since you need to practice, you should start with something
that is well understood and described in MD text books, e.g. velocity
auto-correlations.
axel.