Hi,
I was running a LAMMPS run for the LJ-system using Kokkos (OpenMP) as accelerator for a multi-core CPU (Skylake AVX-512 with 40 physical cores).
First, I ran a job with no accelerator (40 MPI tasks only). It takes 129 sec walltime (128.455 loop-time).
Next, I ran several runs with different settings of Kokkos (OpenMP).
The option “-pk kokkos neigh half newton on comm device binsize 2.8” appears to be most efficient with 40 MPI tasks and 1 OpenMP threads per MPI process and it takes about 158 sec as walltime (153.624 sec as Loop time).
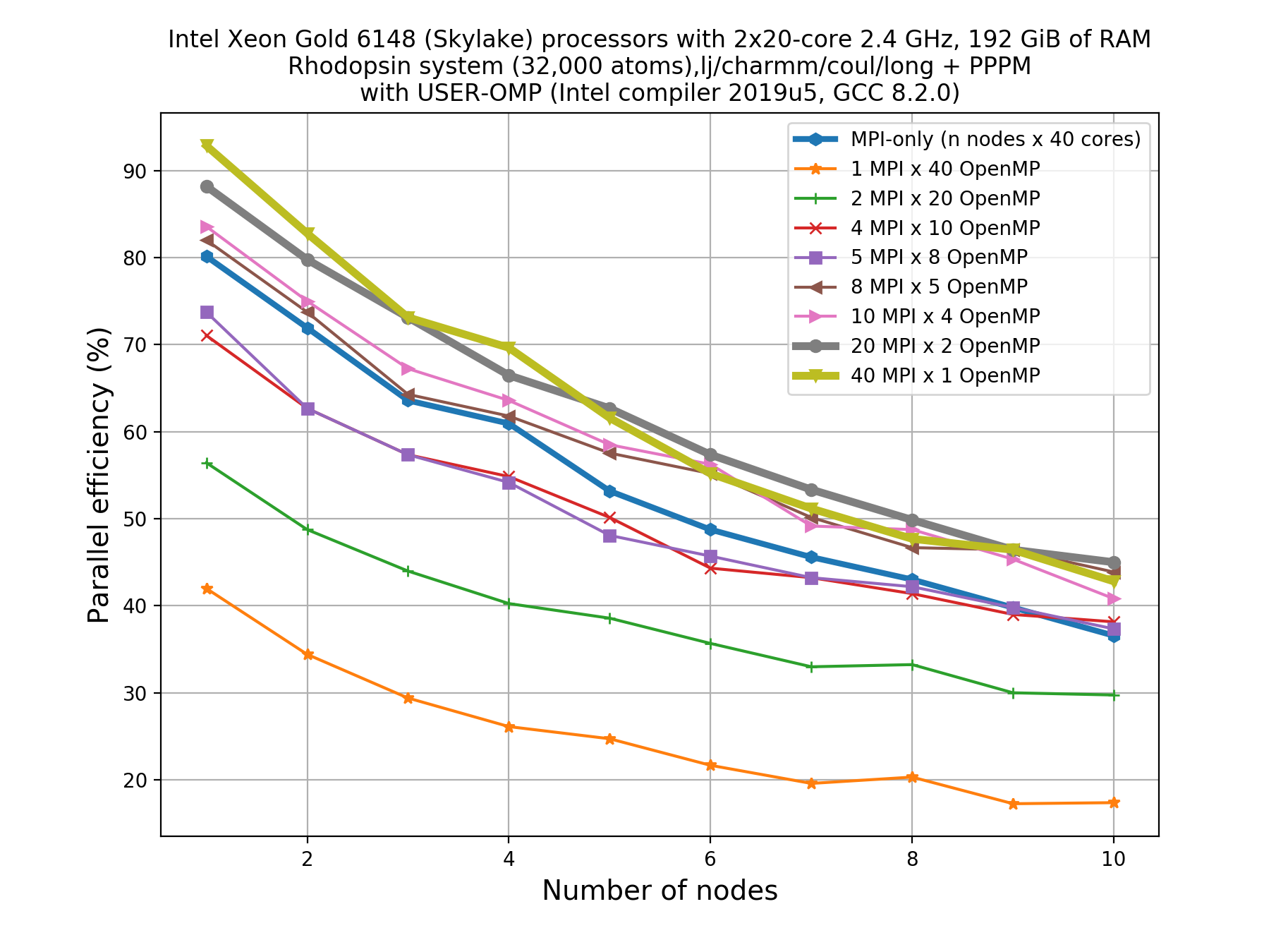
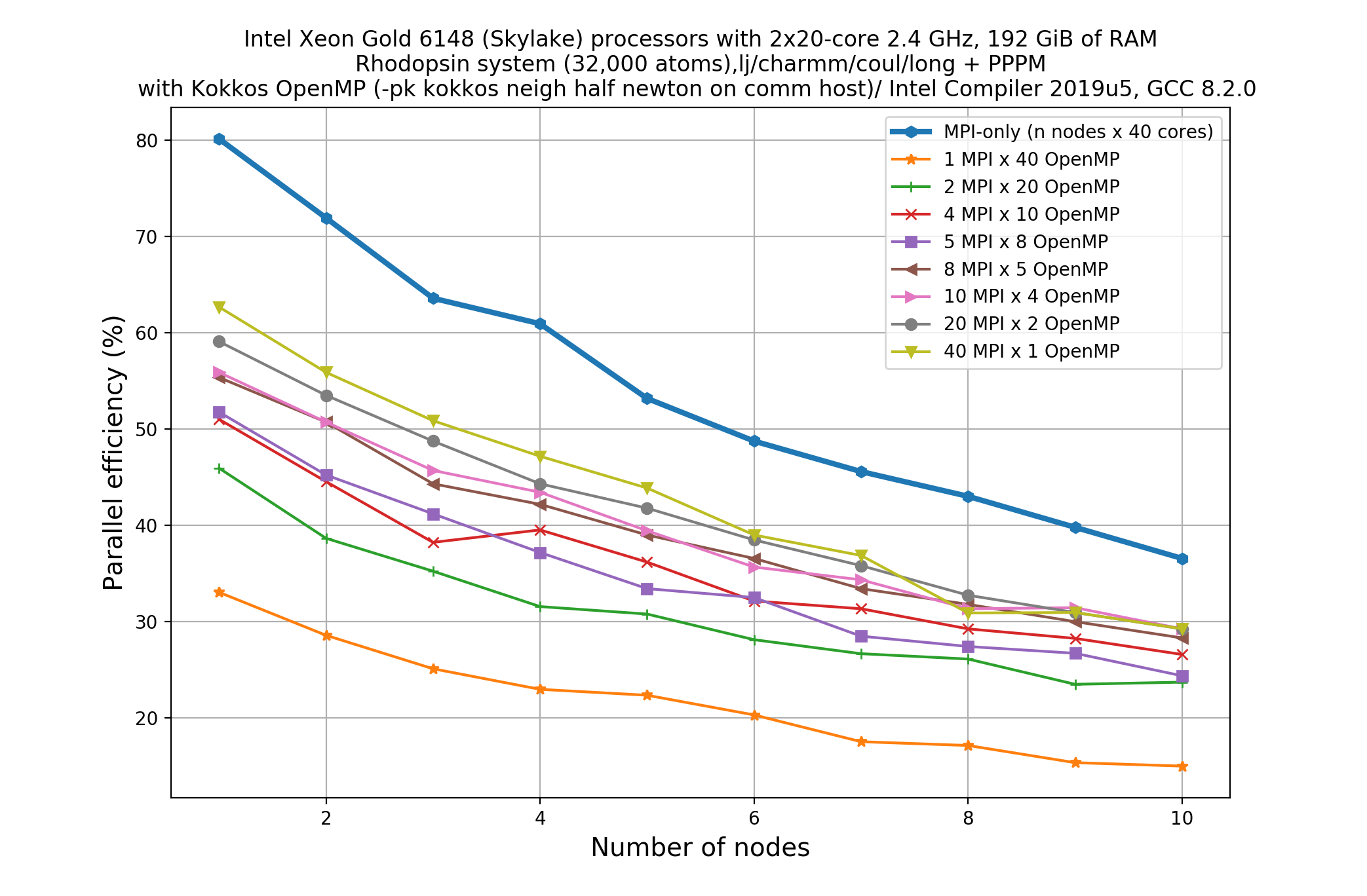
All others MPI/OpenMP threads combinations (e.g. 20MPI/2omp, 10MPI/4omp, 8MPI/5omp, 5MPI/8omp, 4MPI/10omp, 2MPI/20omp, 1MPI/40omp) requires more time to complete the job when compared to the no-Kokkos run with 40MPI/1omp settings.
So, when we compare performance for 1 full-node of a HPC, I am losing performance by using Kokkos (OpenMP).
this is expected behavior. thread parallelization in USER-OMP and USER-INTEL will get similar parallel scaling results.
in USER-INTEL, you can can a little by using single or mixed precision, but the you would still be running faster with all-MPI than with MPI+OpenMP.
This happens because you have a dense, homogeneous, well behaved system with a sufficient number of atoms, so that the MPI parallelization can be at its most efficient. LAMMPS has been constructed from the ground up to do MPI parallel calculations very efficiently using domain decomposition. All other parallelization (being on a device or a host CPU) cannot be as efficient unless you have conditions where the domain decompositions is not as efficient anymore.
Then, why should I use Kokkos (other than portability) when I am losing performance?
because not all systems are as well behaved as this and you are misunderstanding the performance that can be achieved.
using domain decomposition for MD promotes cache efficiency (due to having better cache locality with fewer atoms per process) at the expense of more communication. however, for multi-thread parallelization you parallelize over particles, which is easy to add and compatible (since it is an orthogonal scheme) with domain decomposition. however, for multi-thread parallelism, you need to deal with having to avoid race conditions and false sharing. this can be done by having extra copies of data or using atomic operations or not using newton’s third law. all adds overhead or makes the calculation less efficient.
this relation between MPI parallelism and multi-thread parallelism will change, when the MPI parallelization scheme is less efficient. this will happen, e.g. when you have too few atoms per domain. at some point LAMMPS will scale out and not run
faster or even run slower, if you use more processors via MPI only. with a pair style like lj/cut this will happen at a rather small number of atoms, but if you have long-range electrostatic (via ewald or pppm), then the scaling of kspace will reach its limit
much earlier and you will lose performance overall as the extra overhead from the 3d-FFTs in pppm or the bad O(N^(3/2)) scaling of ewald will drag you down (despite the O(N) scaling of the pair style). at that point using MPI plus a some threads will give you better performance and particularly allows you to scale (i.e. improve total speed) to more total CPUs. The same will also happen, if your domain decomposition is not very well behaved, i.e. you have significant load imbalance. the balance command can help some, but not always, as some system are just pathological. in some cases, you may change the communication pattern to use recursive bisectioning, but using MPI plus thread parallelization can also help, as this will result in larger subdomains for the same number of total processors and usually then will reduce the load imbalance (especially with the help of the balance command). This works because the parallelization over individual atoms in the multi-thread parallelization does not cause (much) load imbalance. that is not to say that the situation cannot be improved. e.g. it would benefit from alternative, per-thread neighbor lists, that would be optimized for reducing the overhead associated with the current multi-thread schemes.
(By the way, I have also tried Kokkos-serial to eliminate OpenMP backend overhead while using 1 OpenMP thread, and this didn’t help!)
there is next to no overhead with just one OpenMP thread when using per-thread copies of data. that is why this scheme is used by default in Kokkos (and is the only choice in USER-OMP).
Or, is there a special trick to gain the acceleration when using Kokkos-OpenMP feature?
you are misunderstanding what kind of “acceleration” you can gain. this should all be explained in the manual, perhaps with less detail as it has to be done in a more general way.
You are also misunderstanding the purpose of Kokkos. The primary reason for Kokkos being develops is that it allows you to write a single pair style in C++ where and without (much) understanding of GPU programming, that will then work on both GPUs (or Xeon Phi) and CPUs with or without multi-threading. It cannot fully reach the performance of USER-INTEL or the GPU package on CPUs and GPUs, but adding new code to those for a pair style, for which something similar already exists, is significantly less effort with Kokkos and requires significantly less programming expertise in vectorization and directive based SIMD programming or CPU computing. Also support for a new kind of computing hardware will primarily need additional code in the Kokkos library and just a little bit of programming setup/management in LAMMPS.
In conclusion. If you run on a CPU-only, you are almost always best off running with MPI-only or just a small number of OpenMP threads on top of mostly MPI.
You should be repeating your experiment on a system with much fewer atoms so you can see the limit of MPI-only strong scaling.
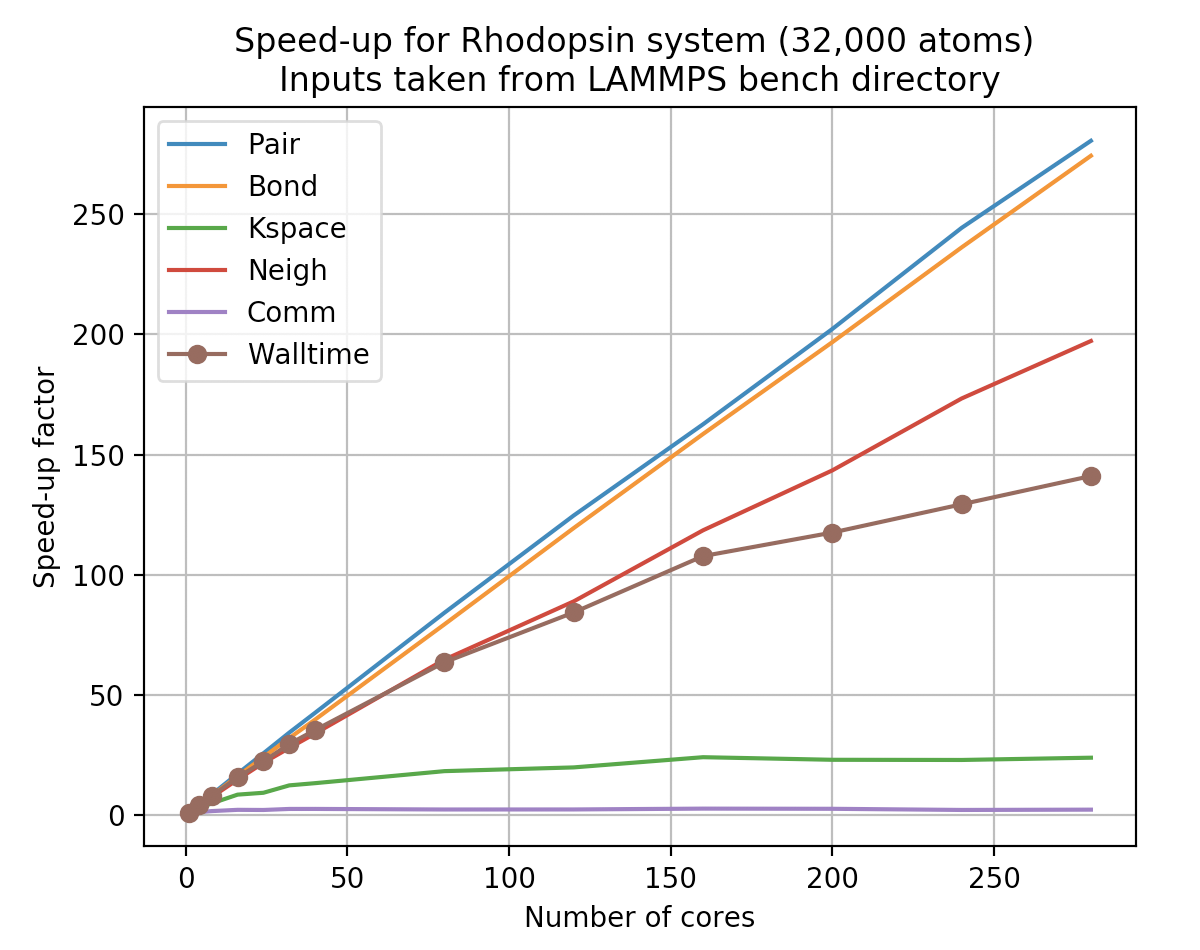
And to understand while I like to call “the curse of the kspace ™”, you should be repeating your experiment with the rhodo benchmark example (also for a large and a not so large number of atoms). You may also want to check out some of the granular media examples, which often have significant load-imbalances, unless special measure are taken to reduce those.
Axel.