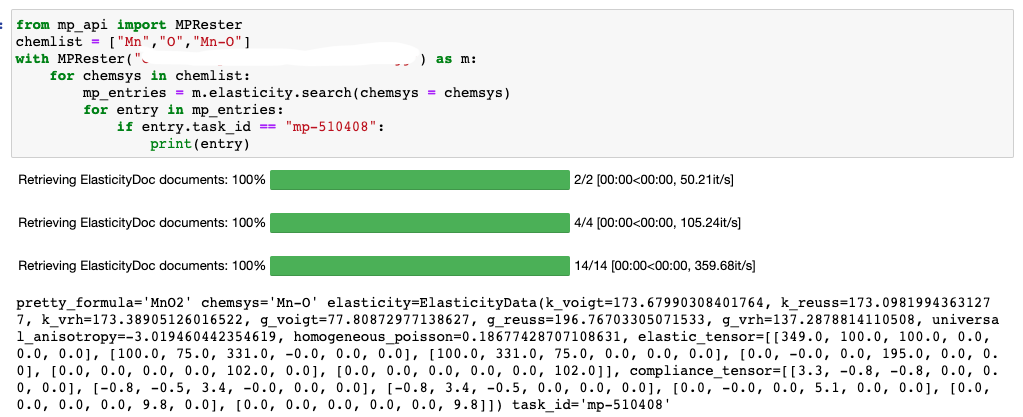
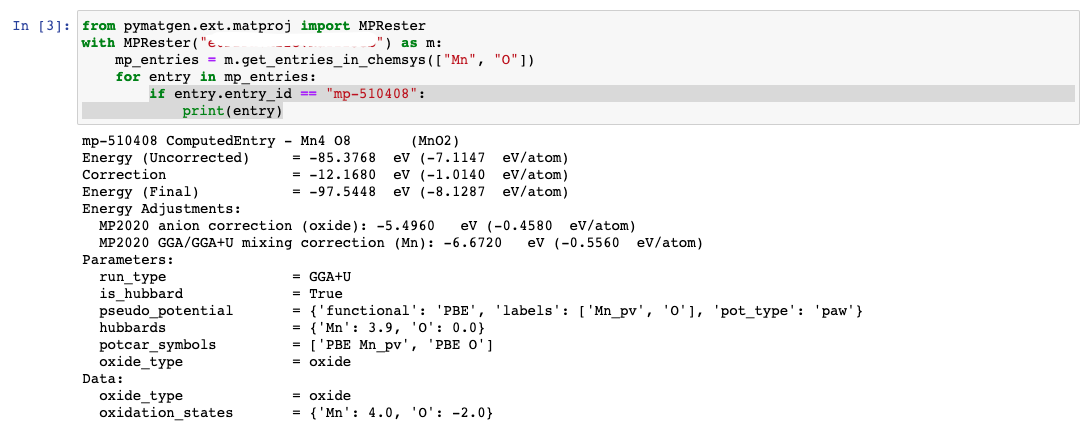
I tried to use both legacy API (pymatgen) and new API (mp_api) for extracting elasticity data. What I found out is that the retrieved data within the same chemical system is different between them.
As it shows, the number of data extracted is different. Legacy API gives 13 entries, but new API gives 2+4+14 = 20 entries. I checked whether beta MnO2 (mp-510408) is in the extracted data, and it is included in the new API, but it is not in the legacy one.
Are some of new calculated results not included in the legacy database?
This is correct; the legacy API is frozen on database version v2020.09.08, and will be indefinitely. The new API is currently running on database version v2021.11.10, which incorporates various fixes and new data. See the get_db_version() method for how to retrieve the database version via code and the Materials Project Database Release Log for more information on historical versions.
Thank you so much.
I have a follow-up question. I also tried to extract all the entries in [“Mn”, “O”] chemical spaces, and in this case, “mp-510408” is only found in the legacy api, rather than new one. This is opposite to the elasticity extraction results. For elasticity data, “mp-510408” is found in new api, but not in legacy one.
There is a subtle but important semantic difference between task_id (identifier for a specific calculation) and material_id (identifier for a material, which aggregates multiple calculations).
Typically the material_id is the smallest/oldest task_id associated with a given material.
The new API is more careful about distinguishing between material_id and task_id, leading to slight differences from the legacy API.
from mp_api import MPRester
with MPRester() as mpr:
thermo_doc = mpr.thermo.get_data_by_id("mp-510408")
print(thermo_doc.material_id) # gives mp-510408
print(thermo_doc.entries["GGA"].data["task_id"]) # gives mp-1271735, the individual calculation
When you retrieve a list of entries using get_entries_in_chemsys, this collects all the entries from the thermo endpoint into a single list. This then contains the task_id for the calculation that was used to give the energy for each entry.
To get the material_id from the task_id, you can use:
To find all task_id associated with a given material_id you can try:
mpr.materials.get_data_by_id("mp-510408").task_ids # returns a list of all ids
In future, it seems that we should store both the material_id and the task_id in the entry so that a lookup is not required. We will add this to our to-do list!
Apologies that this is somewhat confusing. Let me know if you have any further questions.