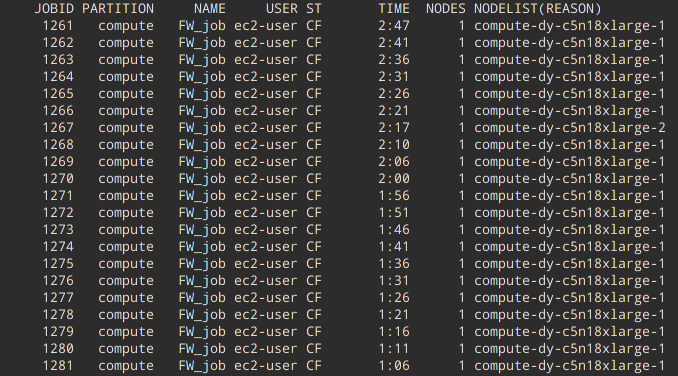
Hi again,
Thanks for all the info, I have not tried it myself, but I think I know now what goes “wrong” (even if it actually is doing the correct thing.) Now that I have the source of the rapidfire line at the end of your script it is easier to answer.
Look at the function definition and its docstring:
def rapidfire(launchpad, fworker, qadapter, launch_dir='.', nlaunches=0, njobs_queue=0,
njobs_block=500, sleep_time=None, reserve=False, strm_lvl='INFO', timeout=None,
fill_mode=False):
"""
Submit many jobs to the queue.
Args:
launchpad (LaunchPad)
fworker (FWorker)
qadapter (QueueAdapterBase)
launch_dir (str): directory where we want to write the blocks
nlaunches (int): total number of launches desired; "infinite" for loop, 0 for one round
njobs_queue (int): stops submitting jobs when njobs_queue jobs are in the queue, 0 for no limit.
If 0 skips the check on the number of jobs in the queue.
njobs_block (int): automatically write a new block when njobs_block jobs are in a single block
sleep_time (int): secs to sleep between rapidfire loop iterations
reserve (bool): Whether to queue in reservation mode
strm_lvl (str): level at which to stream log messages
timeout (int): # of seconds after which to stop the rapidfire process
fill_mode (bool): whether to submit jobs even when there is nothing to run (only in
non-reservation mode)
"""
The default for njobs_queue is 0, which means that unlimited jobs will be submitted, even if nlaunches = 0, which should limit the submission to ‘one round’ whatever that means. (I suspect it means that e.g. nlaunches = 4 and njobs_queue = 2, it will launch jobs until it has 2 in the queue, then wait for for sleep_time, and do the same thing 3 more times.) If you only want one job to run (which will execute all of your fireworks), just replace your last line with:
rapidfire(launchpad, FWorker(), CommonAdapter("SLURM", "fireworks_queue", rocket_launch="rlaunch rapidfire"), reserve=False, njobs_queue=1)
I think the main misunderstanding here is the differentiations of a job on the cluster and a Firework on the LaunchPad. The job has at the time of submission no idea about what calculations are to be run. Once it starts it simply executes a rlaunch rapidfire .... command, which starts pulling calculations from the launchpad that are in the READY state.
Also, the difference between qlaunch rapidfire (launch many jobs) and rlaunch rapidfire (execute many fireworks). I think you wanted to do qlaunch singleshot which submits one job that then executes rlaunch rapidfire on the compute node and thus deals with all 3 FWs that you have.
If you want a single job to only execute a single FW (not very practical) you can get the job also done by launching 3 jobs with qlaunch rapidfire -m 3 (or the equivalent python command with njobs_queue=3) and setting rocket_launch="rlaunch singleshot"
So it is totally fine for FireWorks to launch 20 jobs with only 3 FWs on the LaunchPad. Maybe once they start running you have already added 100 workflows with 1000 Fireworks each, and now all of these jobs have something to do! I think this is actually one of the best features of FireWorks, because you can significantly reduce total queuing time if you use it correctly.