Not sure whether to put this in LAMMPS or Science Talk, but I’ve just read a very nice and detailed reproducibility study comparing simple benchmark systems across different engines:
Would’ve been nice if they’d had NAMD, at least, in the mix. And they incorrectly describe GROMACS as using PPPM (in fact it uses PME). But at least LAMMPS is there and well-represented
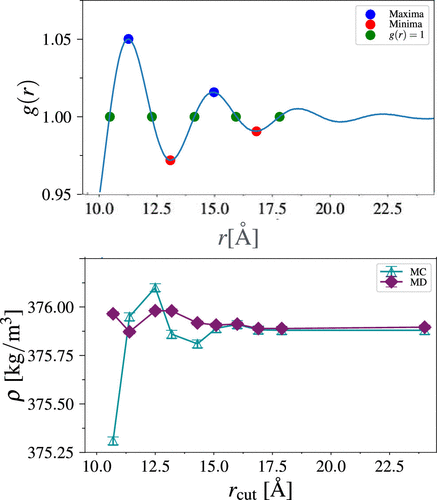
A good graph from the paper shows, below, how both Monte Carlo and MD estimates of density through NpT simulation depend non-trivially on the choice of LJ cutoff (in this case TraPPE-UA methane at 140 K and 1.3 GPa). These deviations are obtained with tail corrections. For perspective, the authors never claim (or even remotely imply) that any one method or engine is unreliable, since, for perspective, the relative deviations are at about 1 part per thousand or under. But these are still statistically observable, and make the point very clearly that both LJ cutoffs and tail corrections (or lack of) are fundamental components of a force field and must be clearly specified for reproducibility.
Having worked with MC codes in the past I am also quite surprised by the differences in size for the error bars between MD and MC but also between different MC codes! This also illustrate the pain that are moves selection and volume change algorithms in MC and how crucial the detailed procedure is required for reproducibility of the simulations. The paragraph in which they detailed how they tried to homogenize the procedure between the 3 codes is explicit.
In a way, even before the current age of “machine learning”, the molecular simulation community has always been dealing with some “hyper parameters communication” problem.
Personally I am not convinced that the MD error bars should be that narrow. There is always partial correlation between snapshots (until proven otherwise); if they took each of their 1ps snapshots as an independent measurement, then they overestimated their sample size and underestimated their standard error of mean (unless they were estimating uncertainties purely from comparing averages between different runs).