Hey Remi,
Rocketsled actually doesn’t have much control over the execution of the workflows themselves-- that is all handled in FireWorks. FireWorks chooses where and when to run jobs; the only thing that rocketsled has control over is what to do when OptTask runs – the rest is handled in FireWorks.
The first step is to add a bunch of workflows including OptTask to the LaunchPad. It does not matter how you submit them.
After that, there are a few different ways to execute the workflows:
A. Use the command line utility “rlaunch” to pull the jobs from the launchpad and run them locally. Specifically, “rlaunch multi $N_PROCESSES --[options]”. This will start multiple parallel processes from the same shell, each running optimization loops. For example if you do “rlaunch multi 10 --nlaunches 20”, this will run 10 parallel processes, each running 20 sequential Fireworks, for a total of 200. So if your job is say, 2 Fireworks (one simulation and one optimization), “rlaunch multi 10 --nlaunches 20” will in total run 200 fw launches/ (2 fws per optimization loop) = 100 optimization loops.
B. In a python file, use the fireworks.scripts.rlaunch_run.launch_multiprocess function. This is the exact same thing as A, but you can use it programmatically in a python file.
C. If you are running on a queueing system, you can use “qlaunch” from the command line. This will launch queue submissions for you; depending on how your qadapter.yaml is set up, compute nodes will pull and run jobs from the LaunchPad in parallel without you having to do anything different. Basically each compute node (or set of compute nodes) will be pulling and running its own jobs in parallel to the others. See (Introduction to FireWorks (workflow software) — FireWorks 2.0.3 documentation) “Executing workflows on different types of computing resources” section for more information.
**If you are running them on your local machine, I prefer (A). If you are running them on HPC, you probably will have to use (C) if you are running in high throughput. **
···
Also, although changing the execution options is done in Fireworks, there are a few options in rocketsled for managing the parallelism of OptTask. The simulations will always run in parallel if that is what FireWorks says to do, but Rocketsled can internally choose what the optimization will do when it starts running. I would recommend just using the default, although I’ll list the other options here too:
**By default, rocketsled runs the simulations in parallel and the optimizations sequentially. This is almost always the best choice for accuracy and convenience, and sounds like what you probably want. **
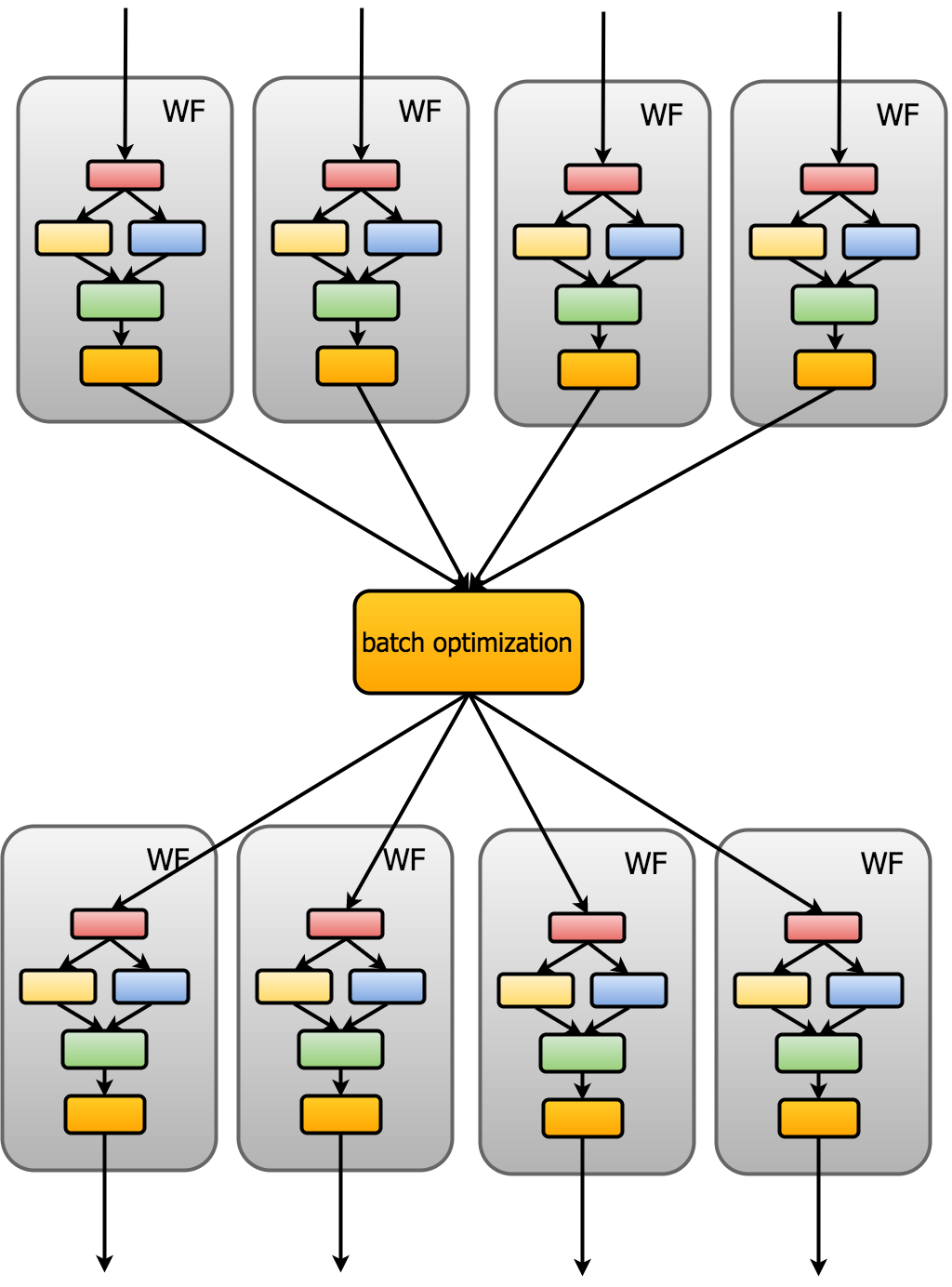
You can also use a batch mode, like the picture shows, by passing in the batch_size argument to OptTask. This is basically the synchronous version of the default, where the simulations run in parallel but only a single optimization runs to choose the next N guesses. This is not recommended for several reasons, but you can use it if you have to.
Finally, you can run OptTask totally in parallel by passing in “enforce_sequential=False” to MissionControl. Again I would not use this option unless you have to, for various reasons, the most important being that no OptTask is guaranteed to have a full set of information when making a prediction.
Note that no matter which one you choose, it will usually appear to the user like everything is happening in parallel (you should see no difference).
Thanks,
Alex
To run the optimization loop in parallel, you shouldn’t need to change anything in the Rocketsled config. By default, it runs the simulation in parallel and runs the optimization in sequence (asynchronously).
On Sunday, February 24, 2019 at 7:06:14 AM UTC-8, Rémi Lehe wrote:
Hi,
I am wondering what is the recommended way to run parallel, asynchronous “streams” of optimization, i.e. where each “streams” performs the typical Rockesled loop (simulation => optimization => submit new simulation), but where the different streams use the same database of x and y.
In other words, I am trying to perform this: https://hackingmaterials.github.io/rocketsled/_images/batch.png but without the synchronization for the optimization, and with a separate optimization after each simulation.
My current understanding is that I could simply run the same rocketsled script several times (once per “stream” without resetting the launchpad inbetween) and this will submit the corresponding set of parallel, asynchronous workflows to the Fireworks database. However, I am wondering if this is the recommended way, or if there is a “cleaner” way to do this?
Thanks!
{kind=link}