Dear all
I have trained a model with Random forest regression for bulk modulus prediction. How do I export this model and predicting?
Any advice would be gratefully appreciated.
Hello Chundo,
You will need to save your model and featurizer with Pickle (Python’s tool for saving and loading variables). Saving them will look something like:
import pickle as pkl
with open('featurizer.pkl', 'wb') as fp:
pkl.dump(feat, fp) # Writes the featurizer to file named "featurizer.pkl"
with open('model.pkl', 'wb') as fp:
pkl.dump(model, fp) # Save the model to "model.pkl"
Once they are saved, you can load them back in later:
import pickle as pkl
with open('featurizer.pkl', 'rb') as fp: # 'rb' means read in _binary_ mode
feat = pkl.load(fp)
with open('model.pkl', 'rb') as fp:
model = pkl.load(fp)
# Run the prediction
X = feat.featurize_many([...])
y_pred = model.predict(X)
Happy to dig into more detail if any of this is unclear.
Dear Logan Ward
Thanks for your kind and helpful reply. I have encountered another problem with using this script on bulk_modulus.ipynb(https://nbviewer.jupyter.org/github/hackingmaterials/matminer_examples/blob/main/matminer_examples/machine_learning-nb/bulk_modulus.ipynb):
I added :
import pickle as pkl
with open(‘featurizer.pkl’, ‘wb’) as fp:
pkl.dump(X, fp) # Save the feature to “featurizer.pkl”
with open(‘model.pkl’, ‘wb’) as fb:
pkl.dump(lr, fb) # Save the model to “model.pkl”
Xa = X.featurize_many([…])
y_pred = model.predict(Xa)
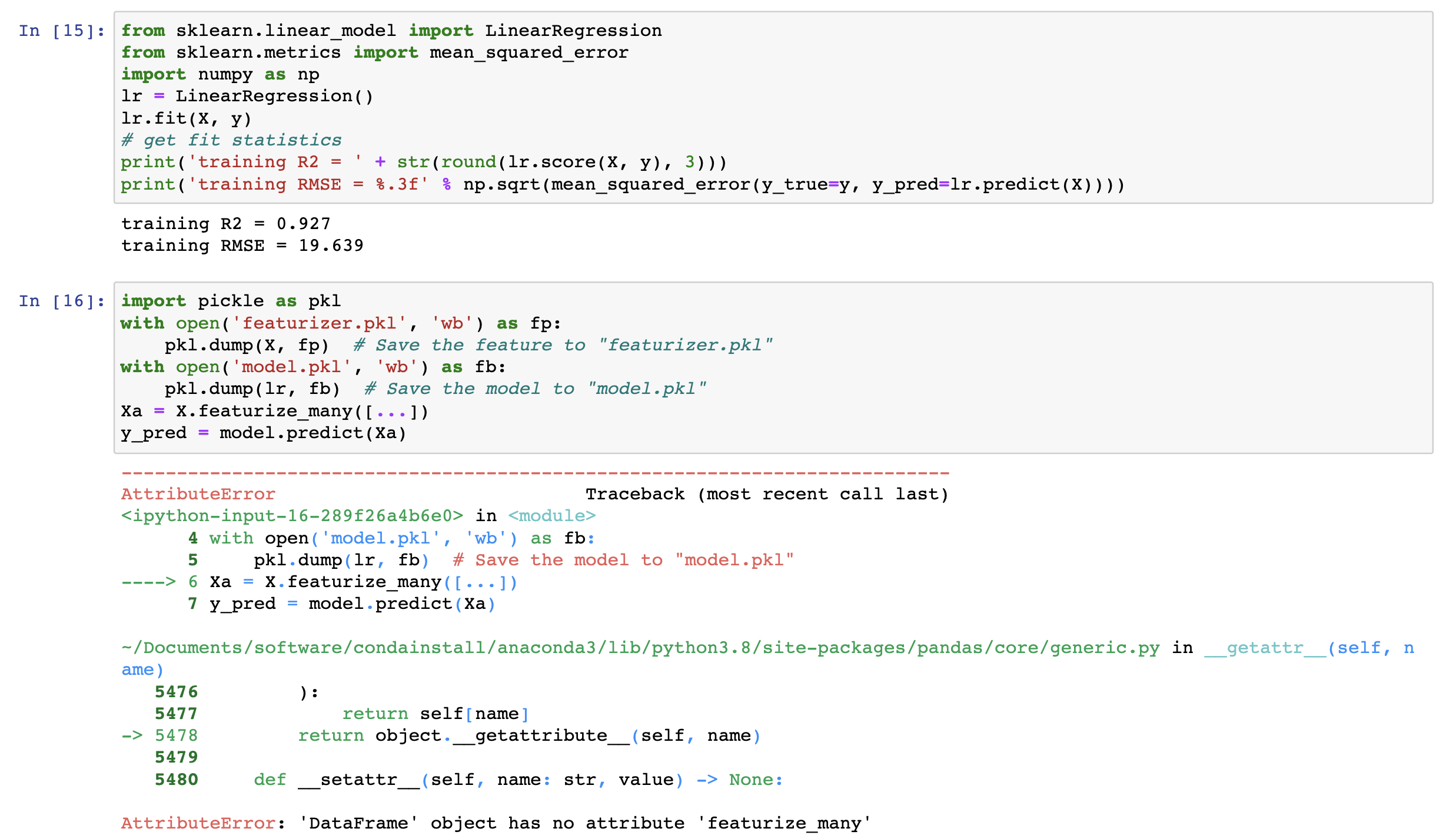
Great, looks like most of it is working.
The line should be feat.fetaurize_many not X.featurize_many
Wait - a quick question. Are you using a Featurizer to compute “X”?
Yes, first I import the original data such as formula, space group, composition for features creation,all features are stored in X. And use the model to calculate that. Under your help, I remodified the script by deleting the Xa = X.featurize_many([…]) . Just y_pred = model.predict(X). It worked for me. Thanks for your helpful and kind reply.
1 Like