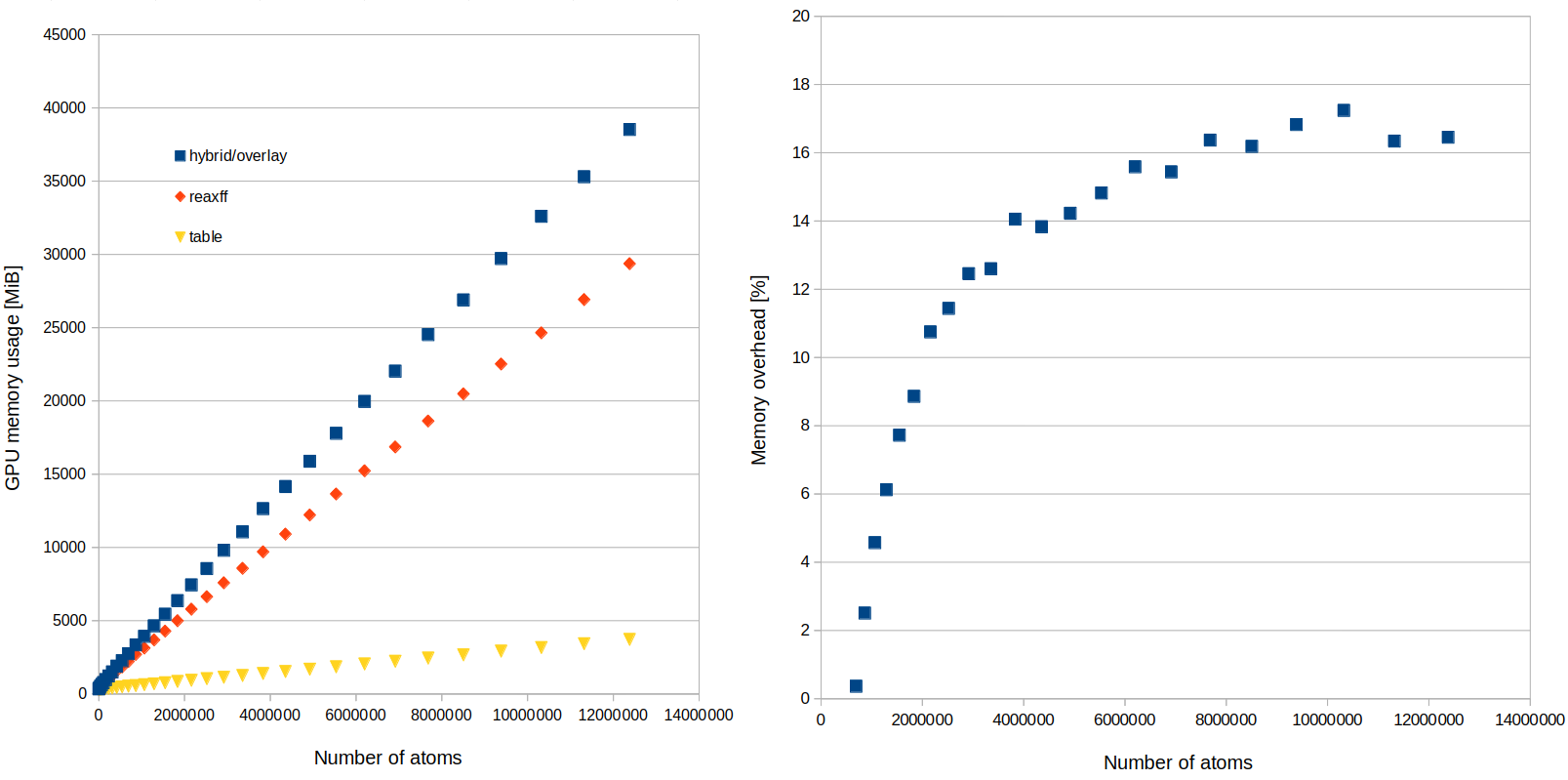
I use GPU acceleration through KOKKOS and I have noticed that when I use pair_style hybrid/overlay with reaxff and table pair_styles, the GPU RAM usage increases faster with the number of atoms than for the pair_styles used separately (for systems large enough). For 5M atoms, hybrid/overlay uses 15% more RAM than the sum of two simulations with the potentials used separately. I wonder if this overhead can be somehow reduced as the GPU RAM is a precious resource. ![]()
LAMMPS version: 4 Feb 2025 - Development - patch_4Feb2025-446-g6f0a59372c-modified
The input script I used for this test is attached at the bottom; it is based on examples/reaxff/ci-reaxFF/ and should work on Linux. I also tried to run the script starting from large systems and it changes nothing, so memory leaks are not an issue.
The GPU RAM usage was measured with nvidia-smi. The graphs below show the GPU memory usage (left) and the overhead (right). I also wonder why the overhead saturates at ~10M atoms.
Input script:
#ci-reax potential for CH systems with tabulated ZBL correction
label loop
variable n loop 34
atom_style charge
units real
read_data CH4.dat
replicate $n $n $n
pair_style hybrid/overlay reaxff control checkqeq no table linear 11000
pair_coeff * * reaxff ffield.ci-reax.CH C H
pair_coeff 1 1 table ci-reaxFF_ZBL.dat CC_cireaxFF
pair_coeff 1 2 table ci-reaxFF_ZBL.dat CH_cireaxFF
pair_coeff 2 2 table ci-reaxFF_ZBL.dat HH_cireaxFF
run 0 post no
shell "nvidia-smi | grep kokkos | awk '{print $(NF-1)}'"
clear
atom_style charge
units real
read_data CH4.dat
replicate $n $n $n
pair_style reaxff control checkqeq no
pair_coeff * * ffield.ci-reax.CH C H
run 0 post no
shell "nvidia-smi | grep kokkos | awk '{print $(NF-1)}'"
clear
atom_style charge
units real
read_data CH4.dat
replicate $n $n $n
pair_style table linear 11000
pair_coeff 1 1 ci-reaxFF_ZBL.dat CC_cireaxFF
pair_coeff 1 2 ci-reaxFF_ZBL.dat CH_cireaxFF
pair_coeff 2 2 ci-reaxFF_ZBL.dat HH_cireaxFF
run 0 post no
shell "nvidia-smi | grep kokkos | awk '{print $(NF-1)}'"
next n
clear
jump SELF loop