Dear lammps-users:
I use the following steps to compile lmp_mpi:
step 0: I have installed the NVIDIA Cuda software on my system.
step 1: I got the num of compute capability : 6.1
step 2: emacs Makifile.linux
step 3: cd …/…/src
step 4: make yes-asphere; make yes-kspace; make yes-gpu
step 5: make gpu
I don’t emac the src/./MAKE/Makefile.linux, because I think this step is useless.
Then I tested a model from benchmark of SPCE. But I am not satisfied with the results. Because the application(lmp_gpu) only accelerated part of the pair and the neighbor . The PPPM part have not been accelerated. I am wondering whta is wrong ?
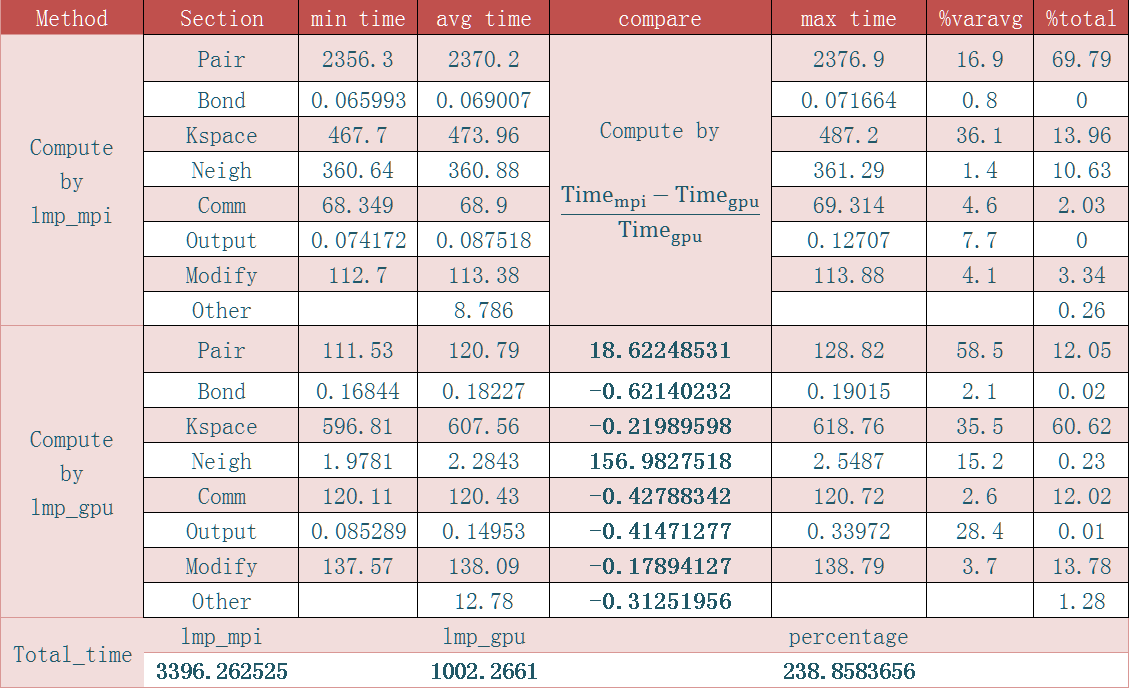
Table 1: the time of system by computation
Thanks for your reading.
Dear lammps-users:
I use the following steps to compile lmp_mpi:
step 0: I have installed the NVIDIA Cuda software on my system.
step 1: I got the num of compute capability : 6.1
step 2: emacs Makifile.linux
step 3: cd ../../src
step 4: make yes-asphere; make yes-kspace; make yes-gpu
step 5: make gpu
I don't emac the src/./MAKE/Makefile.linux, because
I think this step is useless.
Then I tested a model from benchmark of SPCE. But I
am not satisfied with the results. Because the application(lmp_gpu) only
accelerated part of the pair and the neighbor . The PPPM
part have not been accelerated. I am wondering whta is wrong ?
please note, that only part of PPPM operations is GPU accelerated and this
part becomes smaller, the more processors you are using. the GPU
acceleration for pair styles is much more effective. the performance
optimization in heterogeneous computing is not as straightforward, as you
might think. please check out the following discussion, which particularly
applies to running GPU accelerated calculations with multiple MPI ranks.
using the GPU accelerated PPPM kspace style is not always the fastest way
to run. the way how the GPU acceleration in the GPU package works, is that
you can actually use the CPUs and the GPUs at the same time instead of
dispatching both, Pair and Kspace to the GPU. this way you can run the pair
style computation on the GPU while at the same time, you can run Bond and
Kspace on the CPU. in the performance summary, you'll then see a very small
time for Pair and Neigh, because LAMMPS only reports the time spent on the
CPU doing computation or time that the CPU has to wait for the GPU. for as
long as the time for pair is small, you can then try to change the
distribution of time between real-space and reciprocal space by modifying
the (coulomb) cutoff. growing the amount of real space work will reduce the
amount of effort and time spent in Kspace. for as long as the GPU
accelerated pair style work is faster than Kspace on the CPU, the extra
work on the GPU through the longer cutoff is essentially for free.
axel.
Got it. Thanks very much for you letter in reply.
On 05/12/2017 04:50,Axel Kohlmeyer<akohlmey@…24…> wrote: