I am struggling to execute the magnetic ordering workflow on the Stampede2 cluster. I am able to generate workflows and upload them to the fireworks database. However, I have not been able to run vasp jobs with the magnetic ordering workflow in particular. Other workflows such as a relaxation & static calculation or bandstructure calculations work fine. For context, this workflow was generated from the mp-13 Fe structure. The workflow begins, but then fizzles after a timeout. But, the problem does not seem to be time as the calculation should be quick for iron.
my_qadapter.yaml
_fw_name: CommonAdapter
_fw_q_type: SLURM
rocket_launch: rlaunch -c /home1/09282/devonmse/atomate/config rapidfire
nodes: 1
ntasks_per_node: 64
walltime: 4:00:00
queue: normal
account: TG-MAT210016
job_name: null
mail_type: "START,END"
mail_user: [email protected]
pre_rocket: conda activate mag_order
post_rocket: null
logdir: /home1/09282/devonmse/atomate/logs
In each launcher directory the std_err.txt file repeats the following message:
c418-051.stampede2.tacc.utexas.edu.220217PSM2 can't open hfi unit: -1 (err=23)
[37] MPI startup(): tmi fabric is not available and fallback fabric is not enabled
Additionally, the bottom of each OUTCAR has the following warning:
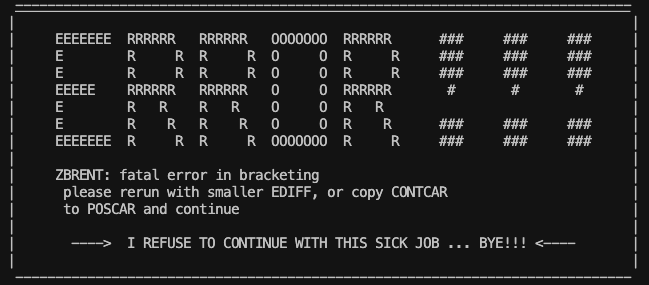
I am interpreting this error as vasp asking me to just rerun the job where I use the CONTCAR from the faulty job as the POSCAR for a new job. However, it seems like this would be awkward to implement for each firework.
Hi Devon,
The magnetic ordering workflow in atomate is just running a series of standard VASP calculations (relaxations/static energy), it is unlikely to be responsible and more likely a VASP issue.
Two thoughts:
-
Have you tried the smaller EDIFF as suggested? Or reviewed how Custodian attempts to correct this error?
-
You could share you complete VASP output directory for the bad job here (except the POTCAR which you should not post). There’s not quite enough information to diagnose.
Best,
Matt
Hey Matt,
I tried a structure with a lower symmetry at the suggestion of one of my colleagues and the ZBRENT error disappeared. However, the job still fails. Honestly, I don’t know how to inspect Custodian attempts. Which vasp output files document Custodian attempts?
Here is a link to a drive with the vasp output directory. vasp outputs - Google Drive
Thanks,
Devon
Hi Devon,
I’m pretty sure this isn’t the magnetic ordering workflow specifically, and just bad luck you encountered this issue here: there’s some deeper issue with VASP related to this specific material + combination of inputs (+ possibly also your specific VASP binary, compute architecture, and parallelisation settings).
Here is the Custodian error correction routines for a zbrent error: custodian/handlers.py at cbfd085b2dd7fe36bda5b6fe1ebdf3ad309fa8fe · materialsproject/custodian · GitHub
Since this is an error related to evaluation of forces, the two main options to try are: (1) try a different minimizer (IBRION tag, if you use VASP with the VTST tools compiled in, this gives you additional options) or (2) dial up the quality of the calculation (make EDIFF smaller, for example, or increase ENCUT, k-point density, etc.), in particular convergence to a smaller EDIFF should be quite rapid.
Hope this helps + good luck!
Matt
It’s possible it’s also unrelated to the zbrent error (since Custodian tries to correct that automatically), and something related to the machine you’re running the calculations on. I see some errors in your std_err.txt like:
c401-001.stampede2.tacc.utexas.edu.4258PSM2 can't open hfi unit: -1 (err=23) [10] MPI startup(): tmi fabric is not available and fallback fabric is not enabled
I’m not sure if these are normal or not, since I’m unfamiliar with your specific HPC system, but perhaps worth looking into?
Hey Matt,
Thanks for your advice! I discussed the MPI startup error with the staff at stampede, and their hunch is the workflow somehow changes the default env, causing the MPI code to not start correctly. They recommended I contact the workflow developers to help debug the workflow in an interactive development session. Do you think debugging the workflow with an interactive dev is an appropriate next step?
The workflow doesn’t change the env, I’m afraid, so not taking responsibility for this one  There is nothing special about this workflow in terms of how it runs VASP, if especially if you’re running other atomate workflows ok.
There is nothing special about this workflow in terms of how it runs VASP, if especially if you’re running other atomate workflows ok.
Check your VASP_CMD too of course, as well as any prelaunch commands (like setting OMP_NUM_THREADS etc.), but this is all standard advice, not specific to this workflow.
If you’re only seeing it with this workflow, it could simply be because it requires tighter force convergence that other workflows, but again that would happen with any calculation and the advice above regarding force convergence would still stand.